2021年の金子の進捗
💡 概要
- 2021年の金子の進捗について振り返る
- 今年はPh.D.を取得したことと新しく岡崎研で働き始めたので主にそれらについて書く
- 他に今年の論文などについても振り返る



タイトル: True Few-Shot Learning with Language Models
著者: Ethan Perez, Douwe Kiela, Kyunghyun Cho
会議・出版: NeurIPS
年: 2021
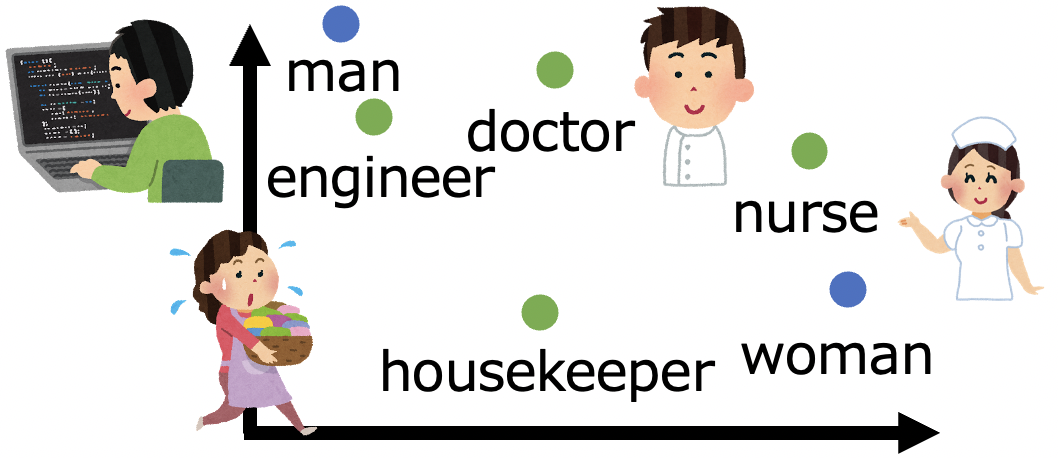
第62回名古屋地区NLPセミナー において,「事前学習された分散表現における公平性」というタイトルで金子が発表した資料です.

タイトル: Null It Out: Guarding Protected Attributes by Iterative Nullspace Projection
著者: Shauli Ravfogel, Yanai Elazar, Hila Gonen, Michael Twiton, Yoav Goldberg
会議・出版: ACL
年: 2020

タイトル: Reducing Sentiment Bias in Language Models via Counterfactual Evaluation
著者: Po-Sen Huang, Huan Zhang, Ray Jiang, Robert Stanforth, Johannes Welbl, Jack Rae, Vishal Maini, Dani Yogatama, Pushmeet Kohli
会議・出版: EMNLP Findings
年: 2020

タイトル: JFLEG: A Fluency Corpus and Benchmark for Grammatical Error Correction
著者: Courtney Napoles, Keisuke Sakaguchi, Joel Tetreault
会議・出版: EACL
年: 2017

タイトル: Debiasing Pre-trained Contextualised Embeddings
著者: Masahiro Kaneko, Danushka Bollegala
会議・出版: EACL
年: 2021

タイトル: Dictionary-based Debiasing of Pre-trained Word Embeddings
著者: Masahiro Kaneko, Danushka Bollegala
会議・出版: EACL
年: 2021

タイトル:Unmasking the Mask – Evaluating Social Biases in Masked Language Models
著者:Masahiro Kaneko, Danushka Bollegala
会議・出版:arXiv
年:2021


