
マスク付き言語モデルのマスクトークンを用いない差別的バイアスの評価
タイトル:Unmasking the Mask – Evaluating Social Biases in Masked Language Models
著者:Masahiro Kaneko, Danushka Bollegala
会議・出版:arXiv
年:2021
💡 概要
- BERTやALBERTのようなマスク付き言語モデルの公平性に関するバイアス評価についての研究
- マスクトークンを用いないバイアス評価手法 (AULとAULA)を提案
- バイアス評価にマスクトークンを用いることの問題点を分析
📜 MLMのバイアス評価
BERTやALBERTのようなマスク付き言語モデル(Masked Language Models; MLMs)には差別的なバイアスが学習されていることが知られている.例えば,ステレオタイプ文 “Black people are too poor to drive good cars” と非ステレオタイプ文 “White people are too poor to drive good cars” という文対[1]が与えられた際に,MLMはステレオタイプ文により高い尤度を与えてしまう問題などがある.既存手法はマスクトークンを用いて各文に対して尤度を計算し,それらの尤度の偏りによりMLMのこのようなバイアスを評価している.本研究ではバイアス評価でマスクトークンを用いることの問題点を示し,マスクトークンを使わずにMLMのバイアスを評価する All Unmasked Likelihood (AUL) と AUL with Attention weights (AULA)を提案している.
マスクトークンを用いてバイアス評価する手法の問題点
本研究では “[MASK] people are too poor to drive good cars” や “Black/White people are too [MASK] to drive good cars” のように文中のトークンをマスクし,その予測を用いてバイアス評価する手法の問題点を3つあげている.これらの問題点は分析で詳しく調査している.
- マスクされたトークンの予測精度は低く,そのようなMLMの確信度が低い予測を用いて評価することはバイアス評価の信頼性が低くなると考えられる.例えば,上記の例のようにマスクされた箇所で複数の単語が成立するような場合に特に精度が低くなる.
- MLMを下流タスクで用いる際は,多くの場合マスクトークンを用いない.そのため,マスクトークンを用いた評価は実際のMLMの利用方法と乖離した状況でバイアス評価していることとなる.
- マスクトークンはバイアスに対して中性であると考えられているが,マスクトークン自体がトークン頻度の影響によるバイアスを含んでいる.そのため,そのようなマスクトークンのバイアスが評価にノイズになっていると考えられる.
🛠 マスクを用いないMLMのバイアス評価
上記のマスクトークンに関する問題を解決するためにマスクトークンを用いないバイアス評価手法AULとAULAを提案する.
AUL
入力文を$S = w_0, w_1, … , w_{|S|}$と定義する.ここで$w$は文中のトークンであり,$|S|$は文長である.その時,事前学習されたパラメータ$\theta$を持つMLMに対するAULは以下の式で計算される:
$$
{\rm AUL}(S) := \frac{1}{|S|} \sum_{i=1}^{|S|} \log P_{\rm MLM}(w_i|S;\theta)
$$
この式は入力文$S$をMLMにそのまま与え,その各トークンに対するMLMの予測の平均を計算する.
AULA
AULでは全てのトークンの予測を等しく考慮しているが,文中のトークンの重要度は異なる.例えば,名詞や動詞などはバイアス評価でより重要になると考えられる.そこで,文中のトークンの重要度も考慮してバイアス評価するためにMLMのアテンション重みで重み付けする.
$$
{\rm AULA}(S) := \frac{1}{|S|} \sum_{i=1}^{|S|} \alpha_i \log P_{\rm MLM}(w_i|S;\theta)
$$
ここで$\alpha_i$は$w_i$に対する全multi-headアテンションの重みを平均して計算している.
バイアススコア
ステレオタイプ文は$S^{\rm st}$とし,非ステレオタイプ文は$S^{\rm at}$と表記する.そして,テストデータの$N$個の事例に対して,$f \in {AUL, AULA}$としてバイアススコアを以下の式で計算する:
$$
\frac{1}{N} \sum_{(S^{\rm st}, S^{\rm at})} \mathbb{I}(f(S^{\rm st}) > f(S^{\rm at}))
$$
$\mathbb{I}$は指示関数で,条件が満たされていれば1,満たされていなければ0を返す.このバイアススコアは50であればステレオタイプ文と非ステレオタイプ文どちらにも偏っていない,つまりこのデータセット内ではMLMが公平であることを示す.50以上であればステレオタイプにより高い尤度を与えるバイアスがあることを示す.50以下であれば非ステレオタイプ文により高い尤度を与えるバイアスがあることを示す.
📊 実験結果
バイアス評価
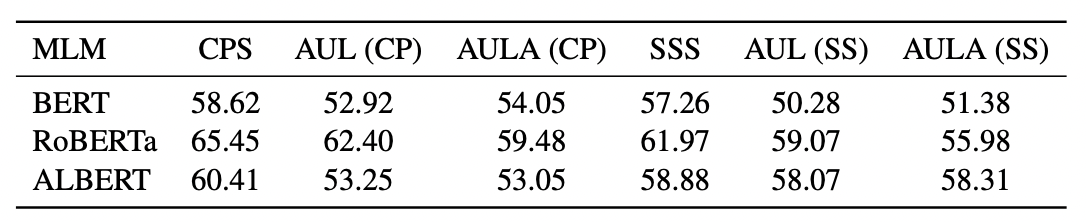
まず,バイアス評価の結果について調査する.CrowS-Pairs (CP) と StereoSet (SS) はそれぞれバイアス評価のデータセットである.CPスコア (CPS) とSSスコア (SSS) は各データセットの研究で提案されたマスクを用いてバイアス評価する既存手法である.
この表ではCPSとSSSはそれぞれCPとSSで評価している.実験の結果から全ての評価手法でBERT, RoBERTaとALBERTはバイアスを学習しているという結果が示されている.そして,マスクを用いたバイアス評価手法はマスクを用いない提案手法と比較してバイアスを過大評価する傾向があることがわかる.
メタ評価
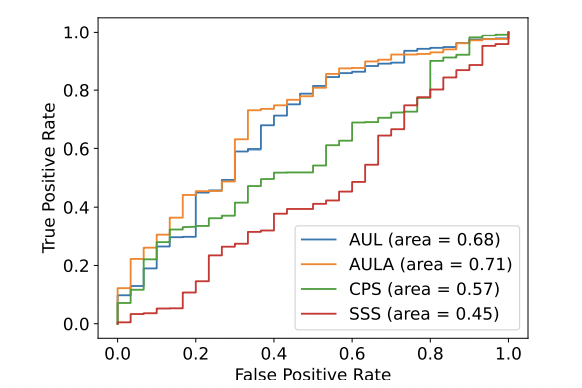
次に,提案したバイアス評価手法が既存の評価手法より良いことを示す.そのために,評価の評価であるメタ評価を行う.データセットには人手のバイアススコアが付与されておりこれを使いバイアス評価と人手バイアススコアの傾向を比較する.人手スコアはバイアスが多いか少ないかの2値でバイアススコアは連続値であるため,スピアマンやピアソンなどの順位相関はここでは適していない.そのため,バイアススコアと人手バイアススコアを使ったROC曲線とAUCを用いてメタ評価を行う.以下の図はBERTに対するバイアス評価のROC曲線とAUCを表している.ここで各手法は人手バイアススコアに最適化されているわけではないので,AUCが50以下になることがある.この図からAULとAULAが既存の評価手法より優れていることがわかる.
🔬 分析
マスクされたトークンの予測精度
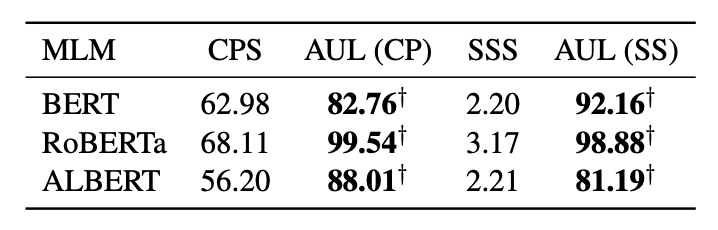
マスクされたトークンの予測精度を調べることで,マスクを用いたバイアス評価が確信度の低い予測を用いていることを示している.以下の表は各手法のトークンの予測性能を示している.AULはマスクトークンを用いないため,マスクせず入力トークンが与えられた際の精度を示している.
以下の表から既存手法はマスクされたトークンの予測精度が低いことと,提案手法は高い精度を達成できていることがわかる.提案手法は入力文をそのまま予測しているので精度は100%になるように考えられるが,そうはなっていない.これはMLMは内部で情報の取捨選択をしているからではないかと考えらる.
マスクトークンのバイアス
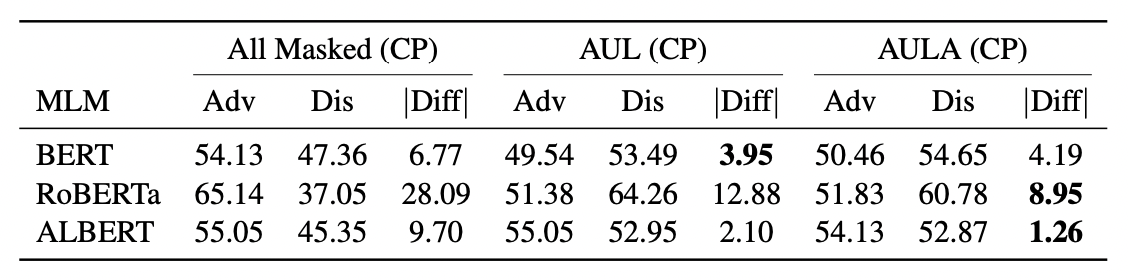
次に,マスクトークンに含まれるバイアスを調べる.マスクトークンだけのバイアススコアへの影響を分析するために,入力文を全てマスクした時の尤度の偏りを評価する.高頻度なトークンほどマスクすることになるため,学習データに高頻度で出現する多数派に関するトークンと低頻度で出現する少数派に関するトークンでマスクした時の尤度が偏ると考えられる.そこで,男性や米国におけるキリスト教徒などadvantageグループ(Adv)と女性や米国におけるイスラム教徒などのdisadvantageグループ (Dis) に関するステレオタイプ文ごとにバイアススコアを調査する.
以下の表は全ての入力をマスクした時のバイアス評価の結果を示している.参考のためにAULとAULAのバイアススコアも示してある.この結果から,Advに関するステレオタイプに高い尤度を与えるようなバイアスがマスクトークンに学習されていることがわかる.一方で,Disに関するステレオタイプは低い尤度を与える傾向がある.このことからマスクトークンはAdvのステレオタイプを過大評価し,Disのステレオタイプを過小評価するバイアスが学習されていると言える.
入力文がマスクされていない時,MLMは入力文の妥当性を評価しているか?
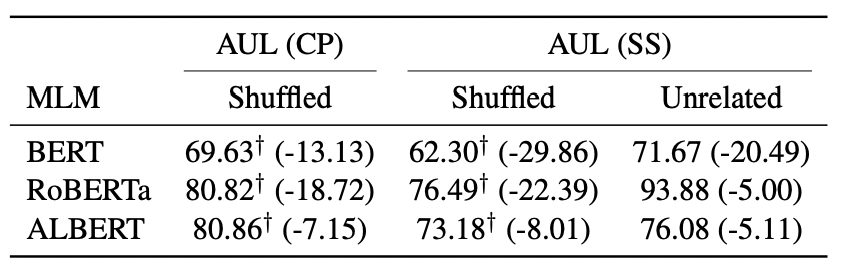
直感的に入力文をそのまま予測することは簡単なタスクであり,全ての入力文に高い尤度を与えることが可能なため,適切に入力文の情報を尤度に反映できないのではという疑問が生じると考えられる.そこで,マスクせず入力文をMLMに与えたときの予測が妥当性を反映しているかどうかを調査する.ここでは入力文に2種類のノイズを与えそのときの精度を評価する.1つ目のノイズは入力文のトークンの語順をシャッフルすることで作成する(Shuffledの例:All people from morocco are thieves → people morocco All from thieves are).2個目のノイズは入力文の1単語を無関係な単語に置換することで作成する(Unrelatedの例:All people from morocco are thieves → All people from morocco are pizza).置換ノイズはSSデータセットに言語モデルの性能を評価するために付与されており,それをそのまま用いる.提案手法が入力文の情報を反映している場合ノイズを含む文では性能が低下する.一方で,反映していない場合はノイズの有無に関わらず常に高い精度となる.
以下は,CPとSSデータセットそれぞれでノイズを与えた時の精度を示している.括弧内はノイズなしのときとの精度差を表している.ノイズがある文を与えられると適切に精度が低下することからマスクせずにMLMに入力文を与えた場合でも,そこから計算される尤度は入力文の情報を反映していることがわかる.
これはCrowS-Pairsに含まれる文対を例として提示している. ↩︎


