辞書を用いた単語分散表現の様々な差別的バイアス除去
タイトル: Dictionary-based Debiasing of Pre-trained Word Embeddings
著者: Masahiro Kaneko, Danushka Bollegala
会議・出版: EACL
年: 2021
💡 概要
- Word2vecやGloVeなどの単語分散表現に含まれる差別的バイアスを除去する研究
- 辞書の定義文を用いることでバイアスに関する単語リストを使わずにバイアス除去する手法を提案
- 性別,人種や年齢など幅広いバイアスに対して有効であることを実証
📜 単語リストを用いないバイアス除去の必要性
単語の情報を実ベクトルに表現する単語分散表現は様々な自然言語処理のタスクで活用されている.しかし,有益な情報と共に差別的なバイアスも学習されている.例えば,$\overrightarrow{nurse}$は$\overrightarrow{he}$より$\overrightarrow{she}$と類似度が高く,$\overrightarrow{doctor}$は$\overrightarrow{she}$より$\overrightarrow{he}$と類似度が高くなると言った性差別的な類似性の偏りなどが知られている.このようなバイアスを単語分散表現から除去するために様々なバイアス除去手法が提案されている.一方で,これらの手法はバイアス除去を学習するためにバイアス単語のリストが必要になる.例えば,性差別のバイアスであればsheやheなど,宗教差別のバイアスであればchristianやmuslimなどで構成される単語リストが必要となる.一方で,差別があってはいけないバイアスを全てリストアップし,そのバイアスに対して十分な量の単語リストを作成することはコストや網羅性の観点から現実的ではない.
バイアスに関連する単語リストを用いずにバイアス除去するために,本研究では辞書の定義文と関連がない情報を単語分散表現から除去することでバイアスを除去する手法を提案する.辞書の定義文は人間により客観的な単語の意味が記述されており,バイアスが含まれていないと仮定できる.定義文と関係する情報を保持し,無関係な情報を除去することで様々なバイアスを除去できることを示す.
🛠 辞書を用いた単語分散表現のバイアス除去
提案手法は3つの損失関数から構成されている.損失関数について説明するためにまずEncoderを定義する.単語$w$に対する単語ベクトルを$\boldsymbol{w}$とする.$\boldsymbol{w}$が入力として与えられたEncoderを$E(\boldsymbol{w};\boldsymbol{\theta}_e)$とする.ここで,$\boldsymbol{\theta}_e$はEncoderのパラメータである.そして,$E(\boldsymbol{w};\boldsymbol{\theta}_e)$をバイアス除去された単語分散表現として最終的に使う.この時,3つの損失関数はそれぞれ以下のように定義される:
1つ目は,定義文と関係する情報を学習する損失関数である.
$$
J_{d}(w) = ||\boldsymbol{s}(w) - D_d(E(\boldsymbol{w}; \boldsymbol{\theta}_e); \boldsymbol{\theta}_d)||^2_2
$$
ここで,$\boldsymbol{s}(w)$は$w$に関する定義文ベクトルである.文に含まれる単語の単語ベクトルから文ベクトルを計算する手法はいくつか提案されている.ここではSmoothed Inverse Frequency (SIF) を用いて定義文ベクトルを計算する.SIFはコーパス内の単語の出現確率の逆数で単語ベクトルを加重平均することで文ベクトルを計算する.この損失関数は中間層から$\boldsymbol{s}(w)$予測することで$E(\boldsymbol{w};\boldsymbol{\theta}_e)$が$\boldsymbol{w}$から$w$の定義文に関連する情報を保持することを目的としている.
2つ目は,定義文と関係しない情報を単語ベクトルから除去する損失関数である.
$$
\begin{align}
J_{a}(w) &= (E(\phi(\boldsymbol{w}, \boldsymbol{s}(w)); \boldsymbol{\theta}_e)^{\top} E(\boldsymbol{w}; \boldsymbol{\theta}_e))^2 \\
\phi(\boldsymbol{w}, \boldsymbol{s}(w)) &= \boldsymbol{w} - \boldsymbol{w}^{\top}\boldsymbol{s}(w) \frac{\boldsymbol{s}(w)}{||\boldsymbol{s}(w)||}
\end{align}
$$
ここで$\phi(\boldsymbol{w}, \boldsymbol{s}(w))$は,$\boldsymbol{w}$と$\boldsymbol{w}$の$\boldsymbol{s}(w)$方向への射影を用いた減算によりベクトルを計算する.このベクトルは$\boldsymbol{w}$に表現されている$\boldsymbol{s}(w)$とは無関係な情報を表している.そして,$\phi(\boldsymbol{w}, \boldsymbol{s}(w))$と$\boldsymbol{w}$をそれぞれ入力として与えられた中間層の内積を最小化することは定義文ベクトルと無関係な情報を除去することを意味している.これにより,差別的バイアス(定義文とは無関係な情報)の除去を行う.
3つ目は,$\boldsymbol{w}$の情報を中間層に学習するための損失関数である.これはAutoencoderの二乗誤差と同様の働きをする.
$$
J_{c}(w) = ||\boldsymbol{w} - D_c(E(\boldsymbol{w}; \boldsymbol{\theta}_e); \boldsymbol{\theta}_c)||^2_2
$$
そして,これらの損失関数を重み付き和で合計することで最終的な損失関数$J(w)$を定義する:
$$
J(w) = \alpha J_c(w) + \beta J_d(w) + \gamma J_a(w)
$$
📊 バイアス評価とバイアスの可視化
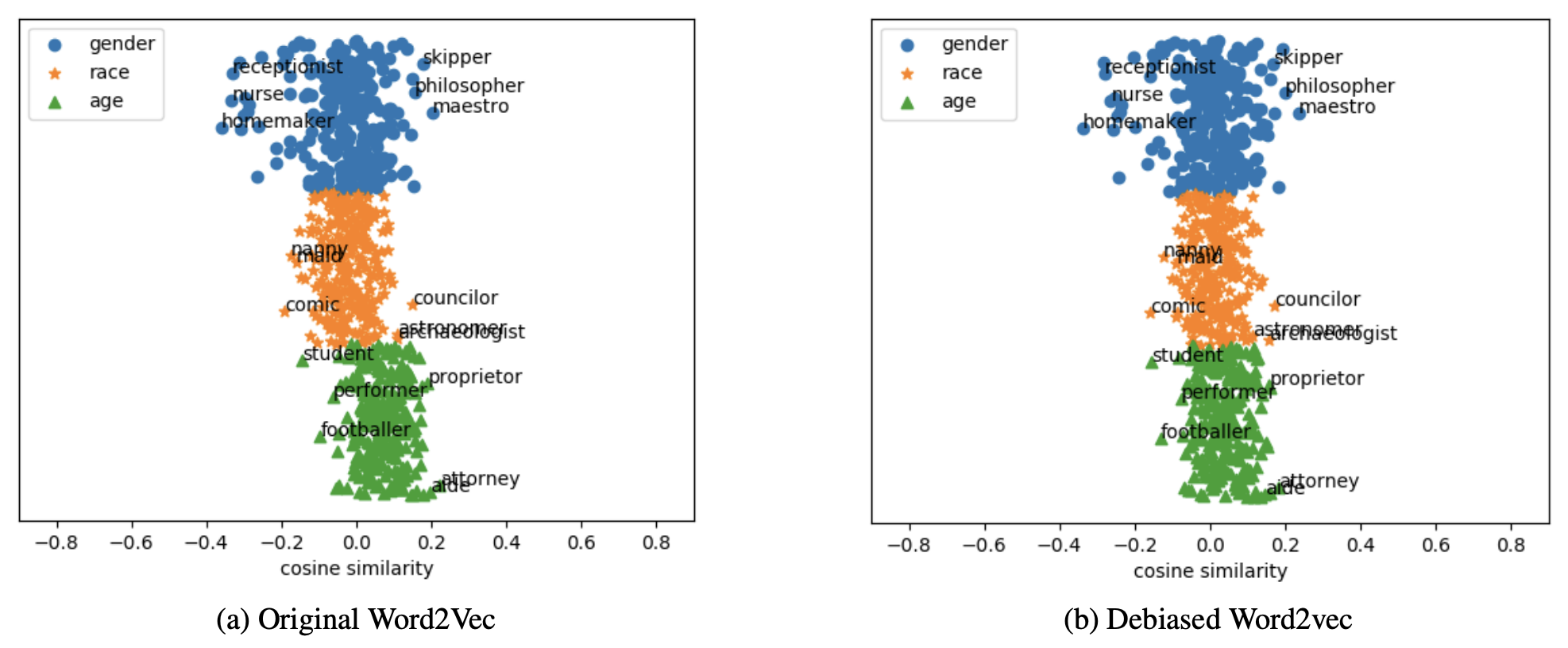
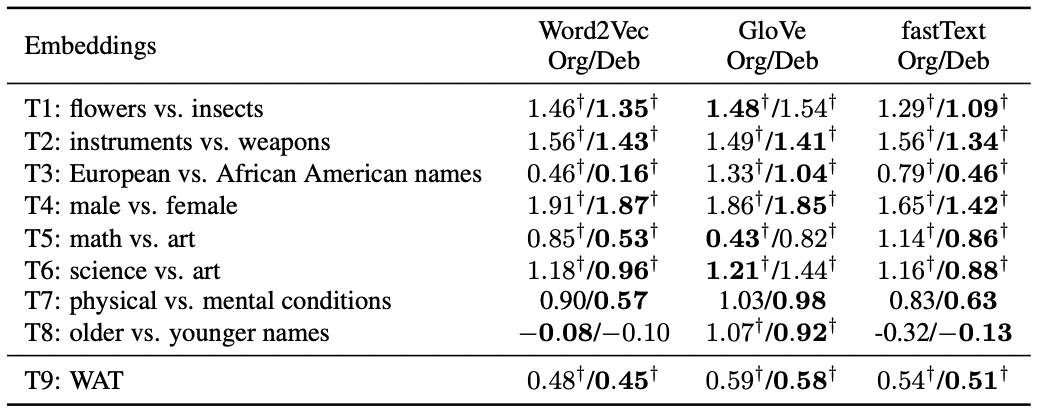
Word2vec, GloVeとfastTextに対して提案手法を適応した.評価データとしてはWord Embedding Association Test (WEAT) とWord Association Test (WAT) を用いる.WEATは性別や人種など単語分散表現の様々なバイアスを評価することができる.WATは性別に関するバイアスを評価することが可能である.WEATとWATはスコアの値が0から離れているほどバイアスがあることを示している.以下の表はオリジナルの単語分散表現 (Org) とバイアス除去した単語分散表現 (Deb) の結果を示している.この結果から,提案手法は単語リストを用いずにさまざまなバイアスを除去できていることがわかる.そして,特にWord2VecとFastTextにおいて効果的にバイアス除去されている.
最後に,Word2vecのバイアス除去前後の単語ベクトルを可視化することで,様々なバイアスを除去できているか調べる.以下の図は,職業単語のベクトルと性別:$\overrightarrow{he} - \overrightarrow{she}$,人種:$\overrightarrow{caucasoid} - \overrightarrow{negroid}$と年齢:$\overrightarrow{elder} - \overrightarrow{youth}$により計算された属性ベクトルとの類似度を示している.各属性ベクトルとの類似度が小さいほど,職業単語が各属性の情報を保持していないことを示しており,バイアスがないことを意味する.この図からバイアス除去することで全体的に0付近に単語が分布するようになっていることがわかる.特に,年齢に関連する単語で顕著な傾向が見られる.