
論文メモ:下流タスクと言語モデル自体の公平性の評価、汎化性のための偽の相関のバイアス除去、正解ラベルなしのプロンプトエンジニアリング
💡 概要
- 下流タスクと言語モデル自体の公平性の評価にはほとんど相関がない
- 汎化性能を高めるために偽の相関によるバイアスを除去する
- 相互情報量による正解ラベルを用いないプロンプトエンジニアリング
下流タスクと言語モデル自体の公平性の評価にはほとんど相関がない
タイトル:On the Intrinsic and Extrinsic Fairness Evaluation Metrics for Contextualized Language Representations
著者:Yang Trista Cao, Yada Pruksachatkun, Kai-Wei Chang, Rahul Gupta, Varun Kumar, Jwala Dhamala, Aram Galstyan
会議・出版: arXiv
年: 2022
複数の評価指標がさまざまなNLPタスクにおける公平性を評価するために提案されている。これらの評価指標は、大きく分けて(1)下流タスクの公平性を評価するための外部評価と(2)文脈付き言語モデル自体の公平性を評価する内部評価の2つに分類できる。
この論文では、19個の文脈付き言語モデルを用いて、外部評価と内部評価の広範囲な相関分析を行う。評価指標の不整合、評価データのノイズ、外部評価の実験構成などの交絡因子を補正した場合でも、外部評価と内部評価は必ずしも相関しないことを明らかにした。そのため、内部評価を用いて言語モデルの公平性を評価する際は、検出に失敗したバイアスが下流タスクの推論時に出現する可能性があることに注意する必要がある。
汎化性能を高めるために偽の相関によるバイアスを除去する
タイトル:Generating Data to Mitigate Spurious Correlations in Natural Language Inference Datasets
著者:Yuxiang Wu, Matt Gardner, Pontus Stenetorp, Pradeep Dasigi
会議・出版: ACL
年: 2022
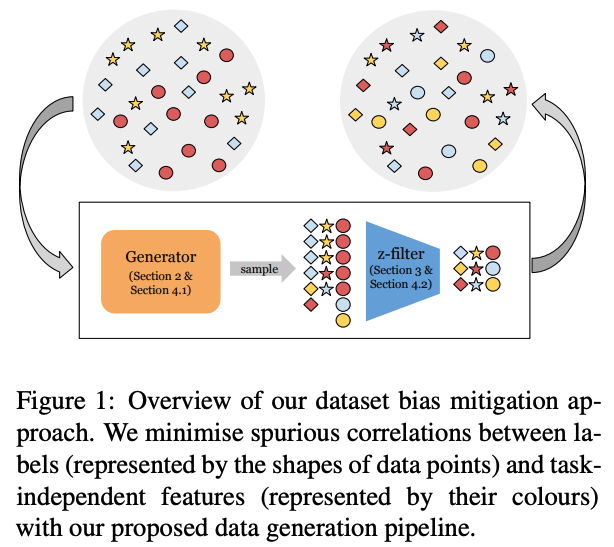
NLPモデルはしばしばデータセットのタスクに依存しない素性とラベルの偽の相関によるバイアスを利用する。これは異なるタスクの分布に汎化しない一方で、学習させた分布内のみで良い性能を発揮する。この論文では、学習データを置き換えるだけで既存モデルの学習に使える、バイアス除去されたデータセットを生成することを提案する。この手法は (1) 高品質でラベルに一貫性のあるデータサンプルを生成するためにデータ生成モデルを学習する手法と(2)Z検定で評価される偽の相関に寄与するデータを除去するフィルター機構、により構成される。
バイアス除去されたSNLIとMNLIデータセットを生成し、バイアス除去されたデータセット、分布外のデータセット、敵対的なデータセットにおいて評価する。結果により、バイアス除去されたデータセットにより学習されたモデルは全ての設定においてオリジナルデータセットで学習されたモデルよりも汎化することがわかった。データセットの大部分で、提案手法は以前のSoTAバイアス除去手法に匹敵または上回り、直交する技術であるproduct-of-expertsを組み合わせた時、さらに改善しSNLI-hardとMNLI-hardにおいて以前の最高性能を上回った。
相互情報量による正解ラベルを用いないプロンプトエンジニアリング
タイトル:An Information-theoretic Approach to Prompt Engineering Without Ground Truth Labels
著者:Taylor Sorensen, Joshua Robinson, Christopher Michael Rytting, Alexander Glenn Shaw, Kyle Jeffrey Rogers, Alexia Pauline Delorey, Mahmoud Khalil, Nancy Fulda, David Wingate
会議・出版: arXiv
年: 2022
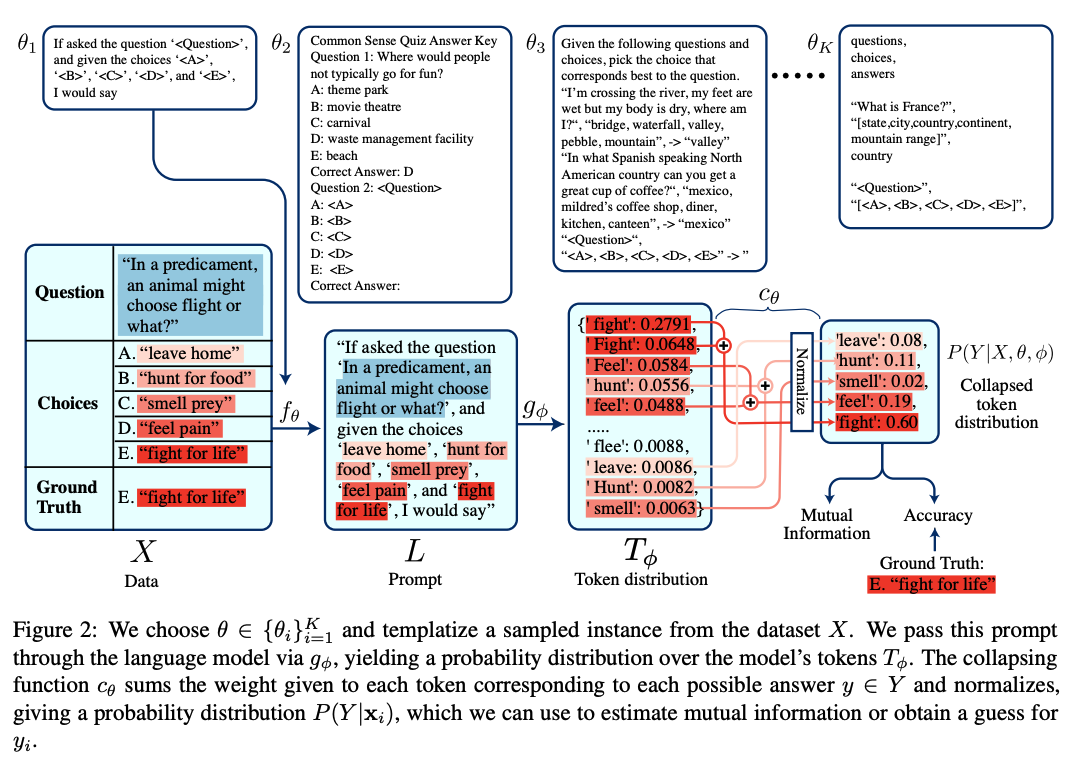
事前学習言語モデルは学習に用いられた膨大なコーパスから言語的・事実的な知識を得ている。プロンプトエンジニアリングはこれらのモデルを特定タスクに適合することを目指す。残念ながら、既存のプロンプトエンジニアリングはたくさんのラベルありデータ、モデルのパラメータへのアクセスやその両方を必要とする。
そのため、ラベル付きの事例とモデルへの直接のアクセスなしにプロンプトテンプレートを選択する手法を提案する。具体的に、候補テンプレートの集合の中から、入力と対応するモデル出力の相互情報量を最大化するテンプレートを選択する。
7つの異なるNLPタスクの8つのデータセットにおいて、高い相互情報量を持つテンプレートの時、高いタスクの性能も達成することを示す。大規模モデルにおいて、提案手法によるプロンプトの選択は、平均的なプロンプトの精度から最高性能のプロンプトの精度までの90%を達成し、そして正解のラベルを必要としない。

