用例を基にした文法誤り訂正モデルを用いた言語学習者のための解釈性
タイトル:Interpretability for Language Learners Using Example-Based Grammatical Error Correction
著者:Masahiro Kaneko, Sho Takase, Ayana Niwa, Naoaki Okazaki
会議・出版: ACL
年: 2022
💡 概要
- 言語学習のための文法誤り訂正モデルは訂正性能だけでなく結果の解釈性についても重要であるが、これまでほとんど議論されてこなかった。
- 近年、予測に用例を用いることで予測の根拠を提示できるようにし、モデルの解釈性を改善する手法が提案されている。言語学習では用例検索システムなどを用いて学習者が文法や語彙を学習することができる。そのため、予測に関連する用例を用いて文法誤り訂正モデルの解釈性を改善することで、同時に学習に有益な用例を提供できると考えられる。
- そこで、本論文では言語学習者の解釈性のために用例を基にして予測を行う文法誤り訂正モデルを提案する。文法誤り訂正の訂正結果と類似する用例を検索し提示することは言語学習者に有益であることを示した。さらに、用例を用いることで文法誤り訂正モデルの性能も改善できることも明らかにした。
📜 文法誤り訂正における解釈性
これまでさまざまなニューラルベースの文法誤り訂正モデルが提案され訂正性能が改善されてきた。一方で、ニューラルベースの文法誤り訂正モデルはブラックボックスであり訂正の根拠を言語学習者に提示することができないため、言語学習者は訂正結果を反映するかの判断が困難であったり、訂正結果から十分に学ぶことができない可能性がある。そして、ニューラルベースの文法誤り訂正モデルにおける解釈性の研究はほとんど行われていない。
言語学習において、用例を提示することで学習者の理解を向上させれることが知られている。例えば、言語学習者は用例を調べることで文法や語彙を習得することに役立つ。さらに、用例検索システムを用いることで作文問題のスコアを改善することもできる。最近の研究では解釈性を改善するためにモデルの予測に用例を用いる手法が提案されている。Khandelwalら (2021)は機械翻訳モデルのデーコーダの表現空間上においてターゲット文の近傍にある用例はソース文の翻訳に役立つことを示した。これらのことから、文法誤り訂正モデルにおける近傍の用例は解釈性を改善し、言語学習者の判断や理解を支援できるのではないかと考えられる。
この論文では、言語学習者に有益な訂正根拠を提示するために用例を用いて文法誤り訂正を行うEample-Based Grammatical Error Correction (EB-GEC) を提案する。下図はEB-GECの概略図を示しており、トークンを予測し文法誤り訂正を行うモデルと訂正と関連する用例(正文と誤文の対)を教師データから検索するモデルを組み合わせている。
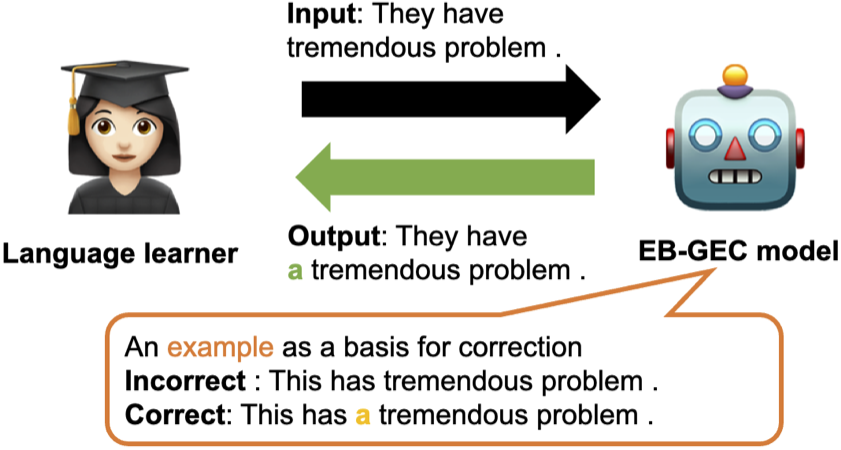
🛠 提案手法:EB-GEC
訂正の予測に用例を考慮するために$k$-Nearest-Neighbor Machine Translation ($k$NN-MT;Khandelwalら, 2021)を基にする。$k$NN-MTは予測時にデコーダの隠れ層の近傍の用例を考慮してトークンを予測する。下図はEB-GECの$k$NN-MTを基にして用例を検索する方法を示している。推論時にエンコーダ・デコーダから計算された分布と近傍の用例から計算された分布の両方を用いてトークンを予測する。
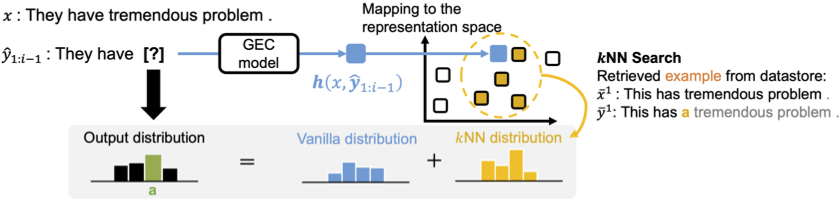
$k$NN-MTを用いた用例の検索
まず、$x=(x_1, …, x_N)$と$y=(y_1, …, y_M)$をそれぞれ文法誤り訂正モデルの入力文と出力文とする。EB-GECの最終的な出力分布$p_{\textrm{EB}}$は、以下の式のように近傍の用例から計算された分布$p_{\textrm{kNN}}$とデーコーダの最終層を線形変換しソフトマックス関数を適用することで計算された分布$p$の線形補間で計算される。ここで$\hat{y}_i$は文法誤り訂正モデルにより出力された$i$番目のターゲットトークンであり、$\lambda$は近傍の用例により計算された分布をどれくらい考慮するかを調整する0以上1以下のハイパーパラメータである。$p$を考慮することで関連する用例がない場合に、出力をより頑健に行えるようになると考えられる。本研究では、解釈性と頑健性の両方を満たすために$\lambda$は0.5とする。
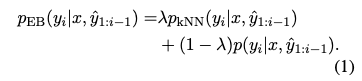
$p_{\textrm{kNN}}$を計算するために、まずデータストア ($\mathcal{K}$, $\mathcal{V}$) を定義する。データストアは検索のための用例を教師データから抽出することで作成される。教師データに対する$i$番目のデーコーダの隠れ層を$\boldsymbol{h}(x,y_{1:i-1})$をキーとし、対応する$i$番目のターゲットトークン$y_i$とその入力・出力文$x, y$をバリューとし以下のようにデータストアを構築する。ここで、$\mathcal{X}$と$\mathcal{Y}$はそれぞれ教師データの全てのソース文とターゲット文である。
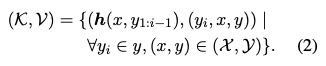
推論時に$x$が入力として文法誤り訂正モデルに与えられたとき、そのデコーダの隠れ層$\boldsymbol{h}(x,y_{1:i-1})$をキーとして作成したデータストアに対して以下のように$k$近傍探索を行う。ここで$\boldsymbol{u}^{(j)}$ ($j = 1, \dots, k$)は$L^2$距離により計算されるキー$\boldsymbol{h}(x,y_{1:i-1})$に対する$k$近傍である。
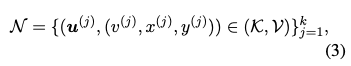
以下のように、検索されたターゲットトークンから負の$L^2$距離を計算し、温度$T$付きソフトマックス関数を用いて分布$p_{\textrm{kNN}}$を計算する。ここで正文と誤文は用いないため_としている。
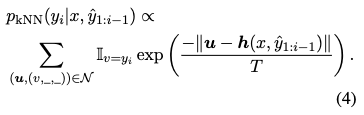
検索した用例の提示方法
データストアの正文と誤文の対を$\hat{y}_i$の訂正根拠となる用例として言語学習者に提示する。ゲシュタルトパターンマッチングにより入力文と訂正文のトークンを対応付けることで、出力文のうちモデルが訂正した箇所だけ用例を提示する。この論文では$k$近傍のうち1-bestの用例だけを根拠として用いる。
📊 実験結果
EB-GECが訂正性能を維持したまま解釈性を改善できているかどうかを調べる。そのために、言語学習者による人手評価と文法誤り訂正のベンチマークデータでの性能を評価する。文法誤り訂正モデルと近傍探索の設定はそれぞれVaswaniら (2017)とKhandelwalら (2021)の研究を基にした。
用例の解釈性に関する人手評価
用例検索のベースラインとして単語の表層一致による用例検索手法 (Token-based retrieval) とBERTの隠れ層を用いた用例検索手法 (BERT-based retrieval) の2つを用いる。文法誤り訂正モデルの訂正結果に対してベースラインの用例検索手法を適用し用例を提示する。
3人の英語学習者が3つの手法の用例330個(合計990個)に対して、訂正結果を反映するかどうかに役立つまたは理解をサポートするかを2値で判定する。下図は各手法ごとに有益であると英語学習者に判断された用例の割合を示している。文法誤り訂正モデルとは独立して用例検索を行う手法よりもEB-GECの方がより有益な用例を提示できていることがわかる。

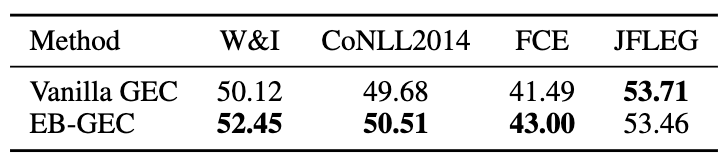
EB-GECのベンチマークにおける訂正性能
文法誤り訂正でよく使われているベンチマークであるW&I, CoNLL2014, FCEとJFLEGを用いて訂正性能の評価を行う。下図は用例を使わない文法誤り訂正モデル (Vanilla GEC) とEB-GECのF$_{0.5}$の結果である。JFLEG以外ではEB-GECの方が結果が良いことがわかる。このことから、EB-GECは性能を犠牲することなく解釈性を改善できていることがわかる。
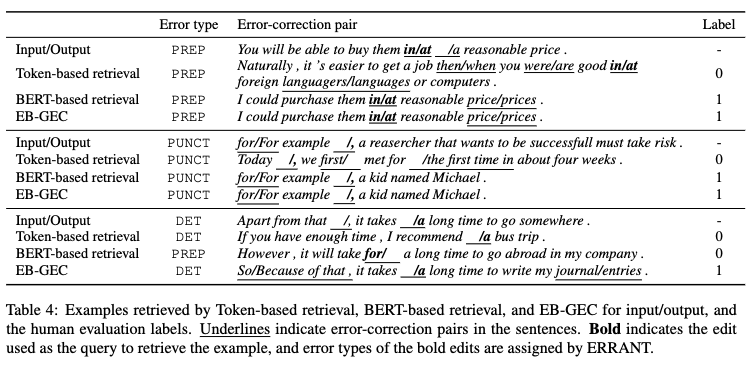
用例検索の例
下図はEB-GEC、Token-based retrievalとBERT-based retrievalそれぞれの手法により検索された用例を示している。Error typeは誤りタイプを表しており、それぞれPREP:前置詞、PUNCT:句読点、DET:冠詞に関する誤りである。Labelはその用例が有益である1または有益ではない0の人手評価である。Token-based retrievalはトークンの表層一致しか考慮していないため、文脈が無関係な用例が提示されており有益ではないと評価されている。BERT-based retrievalは文脈を考慮できているが、最後の用例のように文脈に過剰に影響を受け無関係な訂正を提示してしまっている。一方で、EB-GECは類似した文脈で同じ訂正を持つ用例を提示できていることがわかる。