
マスク付き言語モデルの差別的バイアスの除去
タイトル: Debiasing Pre-trained Contextualised Embeddings
著者: Masahiro Kaneko, Danushka Bollegala
会議・出版: EACL
年: 2021
💡 概要
- BERTやRoBERTaなどのマスク付き言語モデル (Masked Language Models; MLMs) に含まれる差別的バイアスを除去する研究
- MLMのバイアス除去の適応箇所について(1)単語単位と文単位(2)最初の層,最終層と全層,の2つの観点に対して調査した.その結果,単語単位で全層に対してバイアス除去することがもっとも効果的であることを示した.
- そして,MLMごとに下流タスクへの影響に差があることも明らかにした
📜 MLMに対するバイアス除去の課題
MLMは自然言語処理の様々なタスクに用いられ,大幅な性能改善をもたらしてる.一方で,MLMには有益な情報だけでなく,単語分散表現などと同様に差別的なバイアスも学習されていることが知られている.例えば,"This is Adam"と"This is Jamel"という文対が与えられた時,"They are evil"という文との類似度が後者の文と高くなるという人種差別的な類似性が学習されています[1].MLMに対するバイアス削除の研究では以下の3点が課題となる:
- 単語分散表現ではバイアス除去手法は盛んに研究されているが,単語分散表現とMLMではモデルの構造が違うためそれらの手法そのまま適応することが難しい.
- MLMの学習には計算資源や学習時間を必要とするため,fine-tuningのように事前学習されたMLMに適応できるバイアス除去手法が望ましい.
- MLMは多くの手法が提案されており,1つのMLMだけでなくさまざまなMLMに適応できる必要がある.
我々はこれらの課題を踏まえ,MLMの隠れ層を性別ベクトルと直交するようにfine-tuningすることで性差別に関するバイアスを除去する手法を提案する.そして,バイアス除去をMLMにどのように適応することが良いのか以下の図のように(1)単語単位と文単位(2)最初の層,最終層と全層,の2点について調査を行なった.BERT, RoBERTa, ALBERT, DistilBERTとELECTRAの5つのMLMに対して実験を行い,全てのMLMで提案手法はバイアス除去できていることを示した.そして,MLMごとにバイアス除去による下流タスクへの影響が異なること(BERT, DistilBERTとELECTRAでは下流タスクでの性能は少しの低下だけだが,RoBERTaとALBERTでは大幅に低下した.)も明らかにした.
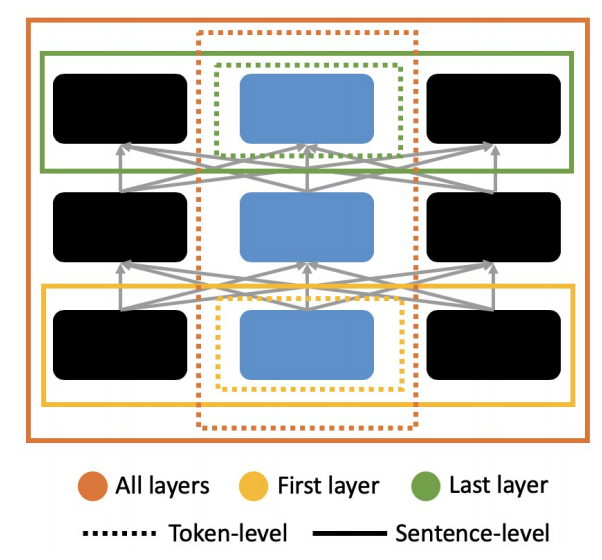
🛠 バイアス除去手法の提案
まず,バイアス除去手法を説明するための定義を行う.sheやheのような性別情報を持つ単語を属性単語$\mathcal{V_{\rm a}}$,nurseやdoctorのような対象単語$\mathcal{V_{\rm t}}$と定義する.そして,単語$w$を含む文を$\Omega(w)$とする.それぞれの単語を含む文の集合を$\mathcal{A} = \bigcup_{w \in \mathcal{V_{\rm a}}} \Omega(w)$と$\mathcal{T} = \bigcup_{w \in \mathcal{V_{\rm t}}} \Omega(w)$と定義する.本研究では,$\mathcal{A}$の事前学習された情報を保持し,$\mathcal{T}$から差別的な性別情報を除去する.事前学習されたハイパーパラメータ$\boldsymbol{\theta}_e$を持つMLM$E$に対してバイアス除去を行う.入力として単語$w$を含む文$x$が与えられ時の$i$層目の$E$の隠れ層は$E_i(w,x;\boldsymbol{\theta}_e)$と定義する.
提案手法は(1)バイアス除去と(2)事前学習された情報の保持,の2つの損失関数により定義される.1つ目のバイアス除去を行う損失関数$L_{i}$は以下の式で表される:
$$
L_{i} = \sum_{t \in \mathcal{V_{\rm t}}} \sum_{x \in \Omega(t)} \sum_{a \in \mathcal{V_{\rm a}}} (\boldsymbol{v}_i(a)^\top E_i(t, x; \boldsymbol{\theta}_e))^2
$$
ここで,${\boldsymbol{v}_i(a)}$は性別情報を表した性別ベクトルであり,$x \in \Omega(a)$に対する隠れ層$E_i(a,x;\boldsymbol{\theta}_e)$の平均により計算される.上記の,損失関数は対象単語を含む文が入力として与えられたとき,隠れ層と性別ベクトルが直交するように学習しており,これによりMLMの隠れ層からバイアスを除去する.この損失関数は文単位でバイアス除去する際,$a$だけでなく$w \in x$に対して計算される.
2つ目の事前学習された情報を保持する損失関数$L_{\rm reg}$は以下の式で表される:
$$
L_{\rm reg} = \sum_{x \in \mathcal{A}} \sum_{w \in x} \sum_{i = 1}^{N} ||E_i(w, x; \boldsymbol{\theta_e}) - E_i(w, x; \boldsymbol{\theta}_{\rm pre})||^2
$$
ここで$N$は文長です.バイアス除去されるMLMと事前学習された重みが固定されたオリジナルMLMの隠れ層が近づくように学習する.これにより事前学習された属性単語の情報を保持される.2つの損失関数の重み付き和を最終的な損失関数とする.
📊 バイアス評価と下流タスクでの結果
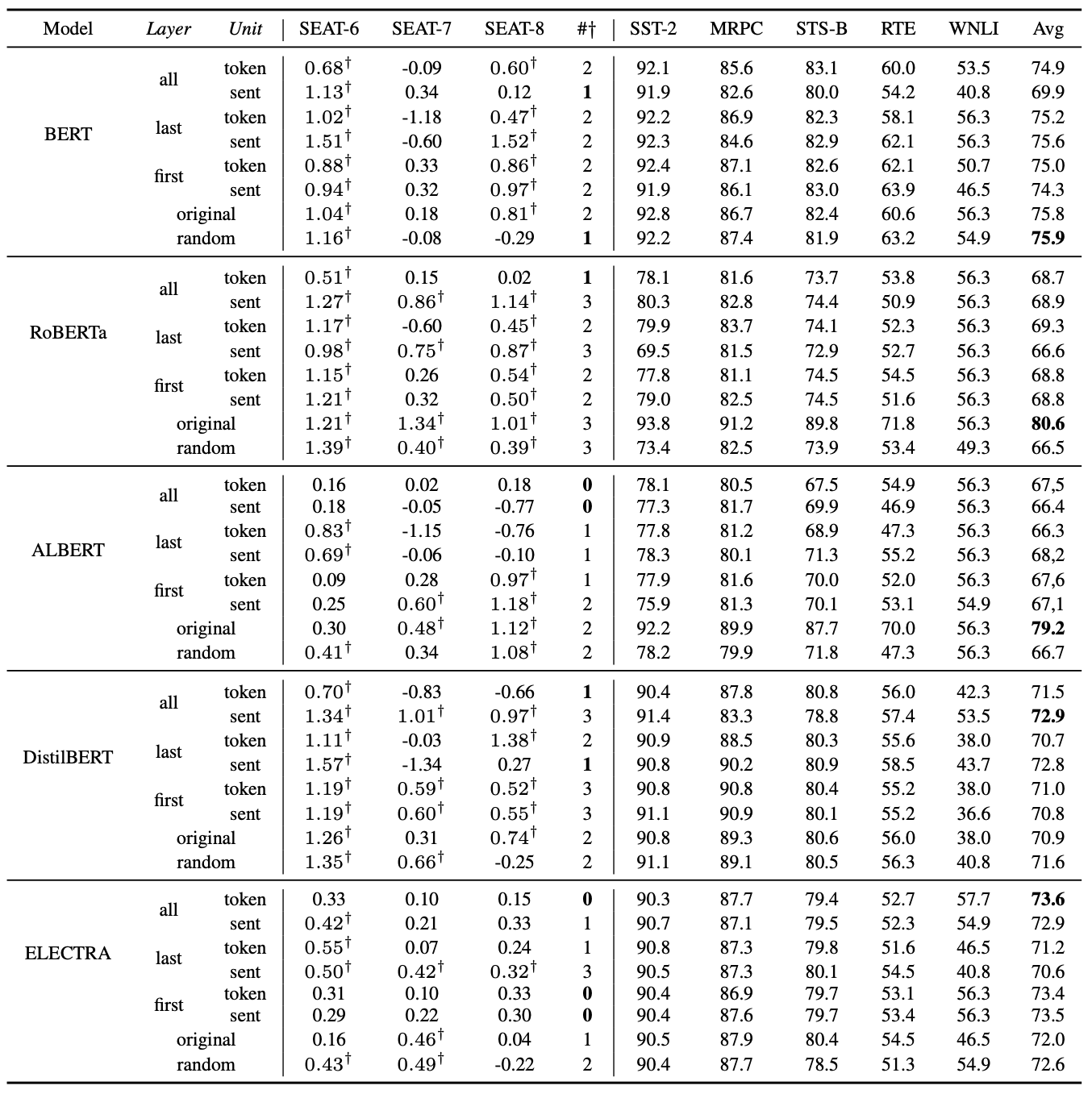
上記の表はSEATの性別に関する3つのバイアス評価とGLEUを用いた下流タスクでの性能評価の結果を示している.SEATでは0に近いほどbiasがなく,GLEUでは100に近いほど性能が良いことを示す.ここでrandomは属性単語と対象単語をシャッフルしてバイアス除去を学習したベースラインである.BERT, DistilBERTとELECTRAではバイアスが除去されながらもGLEUでの性能がほとんど低下していない.一方で,RoBERTaとALBERTではバイアス除去には成功しているがGLEUで大幅に性能が低下している.これらのことから,MLMによってはバイアス除去と事前学習された情報の保持でトレードオフがあることがわかる.そのため,バイアス除去手法はさまざまなMLMに対して適応し評価することが重要である.そして,結果からBERT以外の全てのMLMで単語単位で全ての層からバイアス除去する方法がもっとも効果的であることもわかる.


