
流暢な文法誤り訂正のためのベンチマーク
タイトル: JFLEG: A Fluency Corpus and Benchmark for Grammatical Error Correction
著者: Courtney Napoles, Keisuke Sakaguchi, Joel Tetreault
会議・出版: EACL
年: 2017
💡 概要
- 流暢な文法誤り訂正を評価するための開発・評価データを作成
- 多様な学習者が書いたテキストに対して訂正を行いデータセットを構築
📜 minimal editとfluency editの違い

文法的に誤ったテキストを文法的に正しく書き換えるタスクである文法誤り訂正では訂正方法として(1) minimal editと(2) fluency editの2つの種類がある.
- minimal edit: 文法的に正しくなるように最低限の訂正を行う.そのため,訂正されたテキストがネイティブにとって流暢ではない可能性がある.
- fluency edit: ネイティブが自然と感じるテキストになるような訂正や意味がより明解になるような訂正を行う.そのため,minimal editと比較してより多くの書き換えが行われる.
上記の表はminimal editとfluency editそれぞれの訂正例を示している.例えば,ここでは"an impression so well"をより流暢な"such a good impression"に訂正している.
一方で,既存のGEC評価データはminimal editのみでありfluency editの評価データは存在しない.そのため,fluency editに焦点を当てたJHU FLuency-Extended GUG (JFLEG,ジェーフレッグ) コーパスを作成した.
📊 JFLEGの基本情報
GUGデータセット[1]に対して4人のクラウドワーカーが訂正を行うことでJFLEGを作成する.GUGデータセットは3,129文の英語学習者が書いたさまざまなトピックのエッセイにより構成されている.そのため,JFLEGは多様な学習が書いたテキストに対する文法誤り訂正モデルの性能を評価することができる.
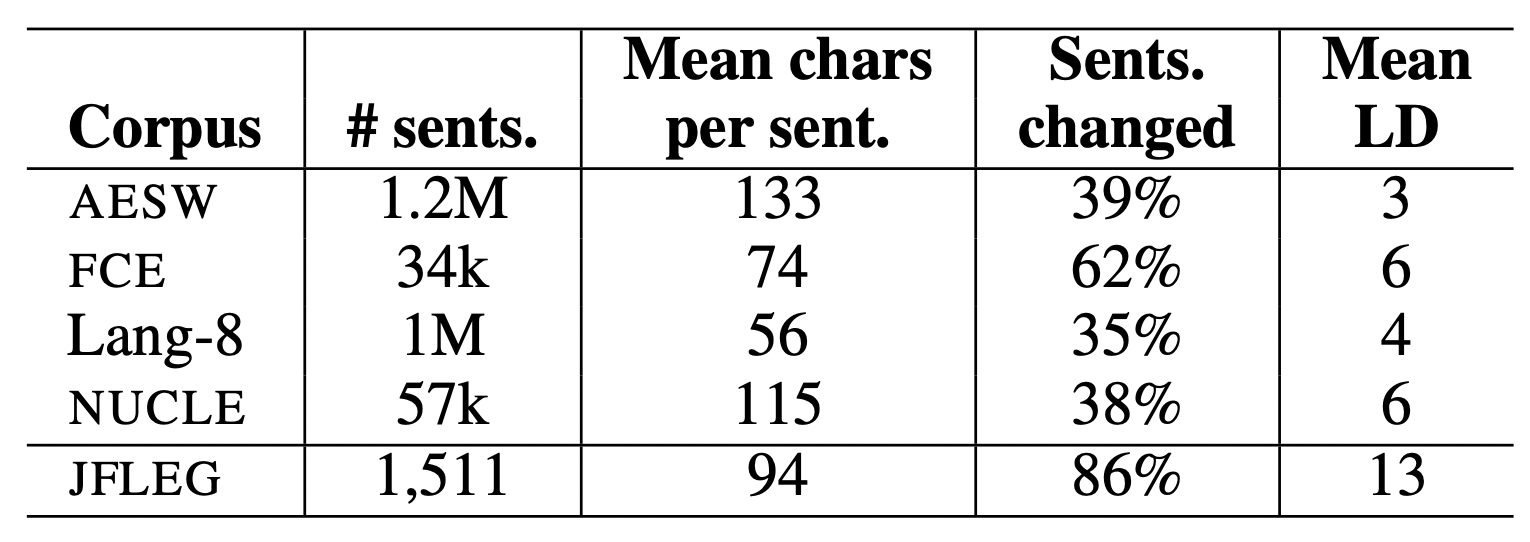
上記の表は既存のGECデータ(AESW, FCE, Lang-8とNUCLE)とJFLEGの統計的情報である.# sents.はデータサイズ,Mean chars per sent.は1文に含まれる平均の文字数,Sents. changedは訂正が行われている文の割合,Mean LDは誤文と正文の平均のレーベンシュタイン距離つまり1文が平均的にどれくらい訂正されたかを示している.JFLEGは開発データ754文であり,テストデータ747文から構成されている.この表からJFLEGが既存のコーパスと比較して積極的な書き換えが行われていることがわかる.


