
プロンプトを用いた言語モデルのFew-shot学習は過大評価されている
タイトル: True Few-Shot Learning with Language Models
著者: Ethan Perez, Douwe Kiela, Kyunghyun Cho
会議・出版: NeurIPS
年: 2021
💡 概要
- 大規模データで事前学習された言語モデルを用いて少数の例のみを用いた学習が注目されている
- 一方で,既存研究ではモデルの選択時に大規模データを使っていたり不明瞭だったりと問題があるため,cross-validationとminimum description lengthを用いてTrue few-shot learning設定で有効であるかどうかを検証した
- True few-shot学習の設定だとモデル選択はかなり困難であることを明らかにし,先行研究では言語モデルのfew-shot学習を大幅に過大評価していることを問題提起している
📜 言語モデルのfew-shot学習
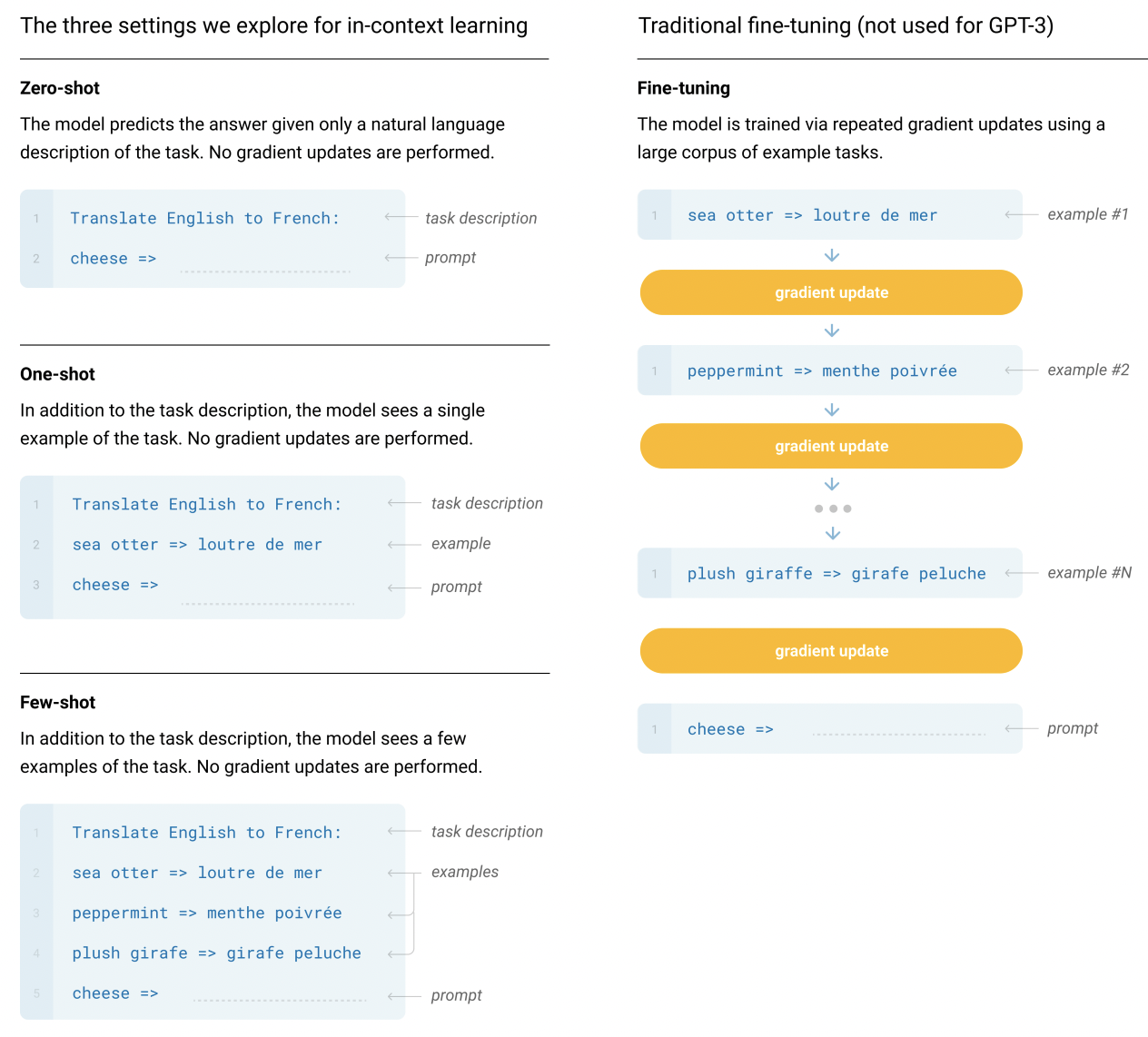
大規模データで事前学習された言語モデルに対してプロンプトを用いたfew-shot学習が注目されている.以下の図(GPT-3の論文より)で示されているように,言語モデルのfew-shot学習では,タスクの説明,例と言語モデルから答えを引き出すプロンプトを用いてタスクを解く.従来のラベル付きデータから教師あり学習をするfine-tuningと違いfew-shot学習では言語モデルのパラメータを更新しない.教師あり学習はデータを豊富にある場合に性能が高い反面,ラベル付きデータを作成するにはコストがかかる.この課題を克服できる可能性があるため言語モデルのfew-shot学習は有望である.
😞 既存のfew-shot学習の問題とその分類
既存の言語モデルでは,学習には小規模な事例を用いているが一方で開発データでは大規模なデータセットを用いたり,他のタスクの開発データを用いられていたりする.このような設定では開発データとして用いた大規模なラベル付きデータを学習データとして用いることができてしまう.つまり,既存のfew-shot学習では多くのラベル付きデータに依存しており,これはfew-shot学習の基準を満たしていないと考えられる.この論文ではこのようなfew-shot学習をTuned few-shot学習と呼ぶ.
この論文では,Tuned few-shot学習に対して大規模な開発データを用いず小規模な学習データと開発データを用いるTrue few-shot学習と呼ぶ.そして,既存のTuned few-shot学習で有効な手法がTrue few-shot学習の設定において有効であるかを調査する.
🛠 True few-shot学習におけるチューニング
True few-shot学習において既存手法が有効であるかどうかを検証する方法について説明する前に,まずfew-shot学習におけるチューニングについて定義する.全てのデータ$D$からサンプルされた学習データ$T \sim D$を用いて学習した後に,開発データ$V \sim D$における汎化誤差$L$を最小化するアルゴリズム(テンプレートの作成方法やいくつ使うかなど)$A^* \in A_1, …, A_a$により決定する,ここで$A(T, R)$は$T$と学習に影響を与えるさまざまなランダム要素$R$(初期化や学習の順番など)をラベル予測する関数にマップする.このとき汎化誤差$L(A(T, R); V)$は開発データ$V$で計算される.
この論文では,交差検証と最小記述長によりプロンプトを用いた言語モデルのTrue few-shot学習の設定で検証する.
交差検証
交差検証ではランダムに$T$を$K$個の等しいサイズのデータ$F(T)^1, …, F(T)^K$に分割する.そして,学習に用いたデータ$F(T)^{\lnot k}$の残りを開発データ$F(T)^k$とし,$F(T)^k$における損失の平均を評価することでチューニングする,式で表すと以下のようになる:
$$
CV(A, R, F) = \mathbb{E}_{k \sim {\rm Unif}(1, K)} [L(A(F(T)^{\lnot k},R); F(T)^k)]
$$
最小記述長
最小記述長では$k$番目までのデータを学習に用いて,$k$番目のデータを開発データとし損失の平均で評価を行う.式で表すと以下のようになる:
$$
MDL(A, R, F) = \mathbb{E}_{k \sim {\rm Unif}(1, K)} [L(A(F(T)^{1:k-1},R); F(T)^k)]
$$
📊 実験結果
まず,事前学習された言語モデルの事実や常識を評価するデータセットであるLAnguage Model Analysis (LAMA)を用いてGPTのTrue few-shot学習設定の性能を評価する.交差検証と最小記述長を用いてプロンプトの作成方法(人手での作成やWikipediaからの抽出など)をチューニングする.
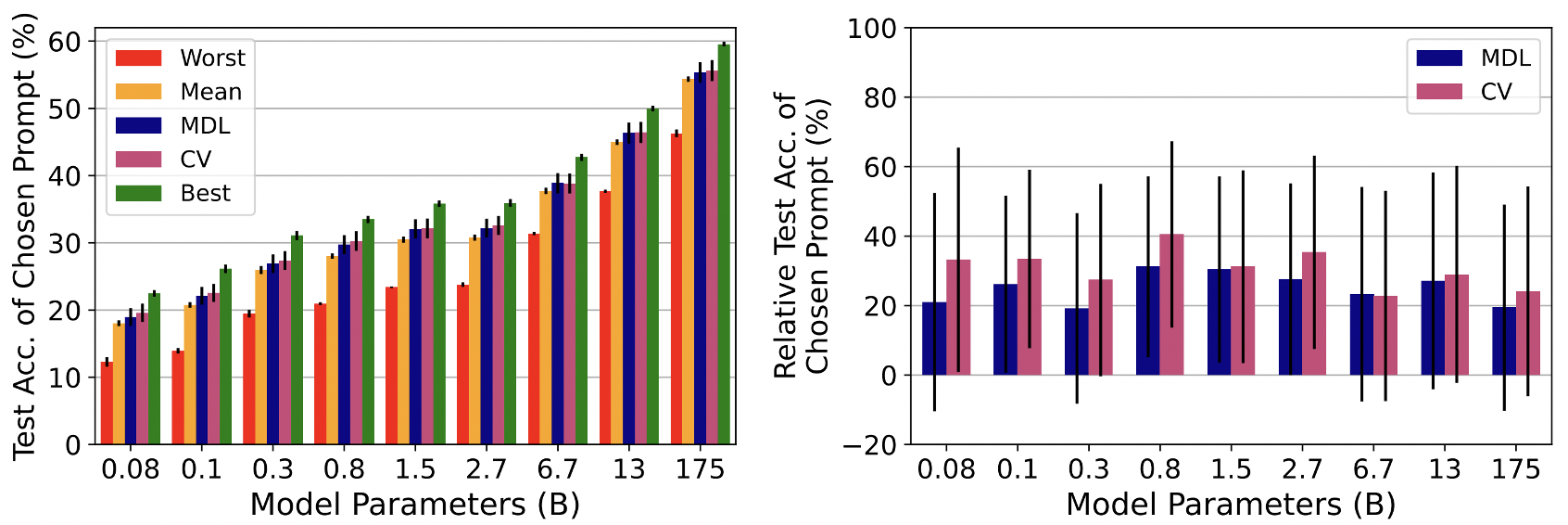
上記の左図はLAMAにおけるGPTの性能を表している.縦軸が性能であり,横軸がGPTのモデルサイズである.Worstは最も性能が悪いプロンプトの結果,Meanはランダムにプロンプトを選択した結果,MDLは最小記述長を用いた結果,CVは交差検証を用いた結果,Bestは大規模な検証データを用いるTuned few-shotの結果である.そして,右図はMDLとCVそれぞれのMeanからのBestと比較した改善割合を示している.0%はMeanから改善なしで100%がBestと同等の改善を意味している.これらの結果から,True few-shot学習の設定ではBestと比較してほとんど改善していない,ランダムにプロンプトを選択した時と同程度であることがわかる.これはTrue few-shot学習の設定では適切なプロンプトを選択することが難しいといえる.そして,既存研究では言語モデルにおけるfew-shot学習は過大評価されていると考えられる.
📍 few-shot学習の今後について
このような既存の言語モデルにおけるfew-shot学習の問題を解決するために,最後に以下のようなことをお勧めしている:
- 全てのハイパーパラメータを報告する
- 学習データと開発データ両方のデータサイズを報告する
- 既存研究のハイパラをそのまま使わずに,小規模な開発データで自分でチューニングしたハイパーパラメータを用いる.


