論文メモ:データ選択における著者バイアス、マルチモーダルの構造を調査、言語モデルと知識グラフを用いたQAモデル
💡 概要
- テキストデータ選択手法には特定の著者の属性を優遇する
- マルチモーダルモデルの事前学習データ、アテンション機構と損失関数について調査
- 言語モデルと知識グラフを相互に考慮したQAシステム




タイトル: True Few-Shot Learning with Language Models
著者: Ethan Perez, Douwe Kiela, Kyunghyun Cho
会議・出版: NeurIPS
年: 2021
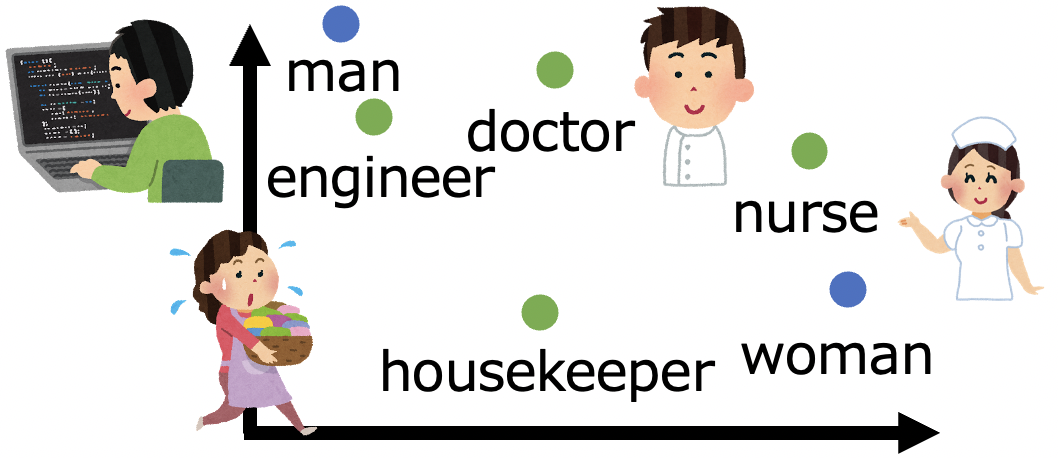
第62回名古屋地区NLPセミナー において,「事前学習された分散表現における公平性」というタイトルで金子が発表した資料です.

タイトル: Null It Out: Guarding Protected Attributes by Iterative Nullspace Projection
著者: Shauli Ravfogel, Yanai Elazar, Hila Gonen, Michael Twiton, Yoav Goldberg
会議・出版: ACL
年: 2020

タイトル: Reducing Sentiment Bias in Language Models via Counterfactual Evaluation
著者: Po-Sen Huang, Huan Zhang, Ray Jiang, Robert Stanforth, Johannes Welbl, Jack Rae, Vishal Maini, Dani Yogatama, Pushmeet Kohli
会議・出版: EMNLP Findings
年: 2020

タイトル: JFLEG: A Fluency Corpus and Benchmark for Grammatical Error Correction
著者: Courtney Napoles, Keisuke Sakaguchi, Joel Tetreault
会議・出版: EACL
年: 2017

タイトル: Debiasing Pre-trained Contextualised Embeddings
著者: Masahiro Kaneko, Danushka Bollegala
会議・出版: EACL
年: 2021

タイトル: Dictionary-based Debiasing of Pre-trained Word Embeddings
著者: Masahiro Kaneko, Danushka Bollegala
会議・出版: EACL
年: 2021

