
論文メモ:データ選択における著者バイアス、マルチモーダルの構造を調査、言語モデルと知識グラフを用いたQAモデル
💡 概要
- テキストデータ選択手法には特定の著者の属性を優遇する
- マルチモーダルモデルの事前学習データ、アテンション機構と損失関数について調査
- 言語モデルと知識グラフを相互に考慮したQAシステム
テキストデータ選択手法には特定の著者の属性を優遇する
タイトル: Whose Language Counts as High Quality? Measuring Language Ideologies in Text Data Selection
著者:Suchin Gururangan, Dallas Card, Sarah K. Drier, Emily K. Gade, Leroy Z. Wang, Zeyu Wang, Luke Zettlemoyer, Noah A. Smith
会議・出版: arXiv
年: 2022
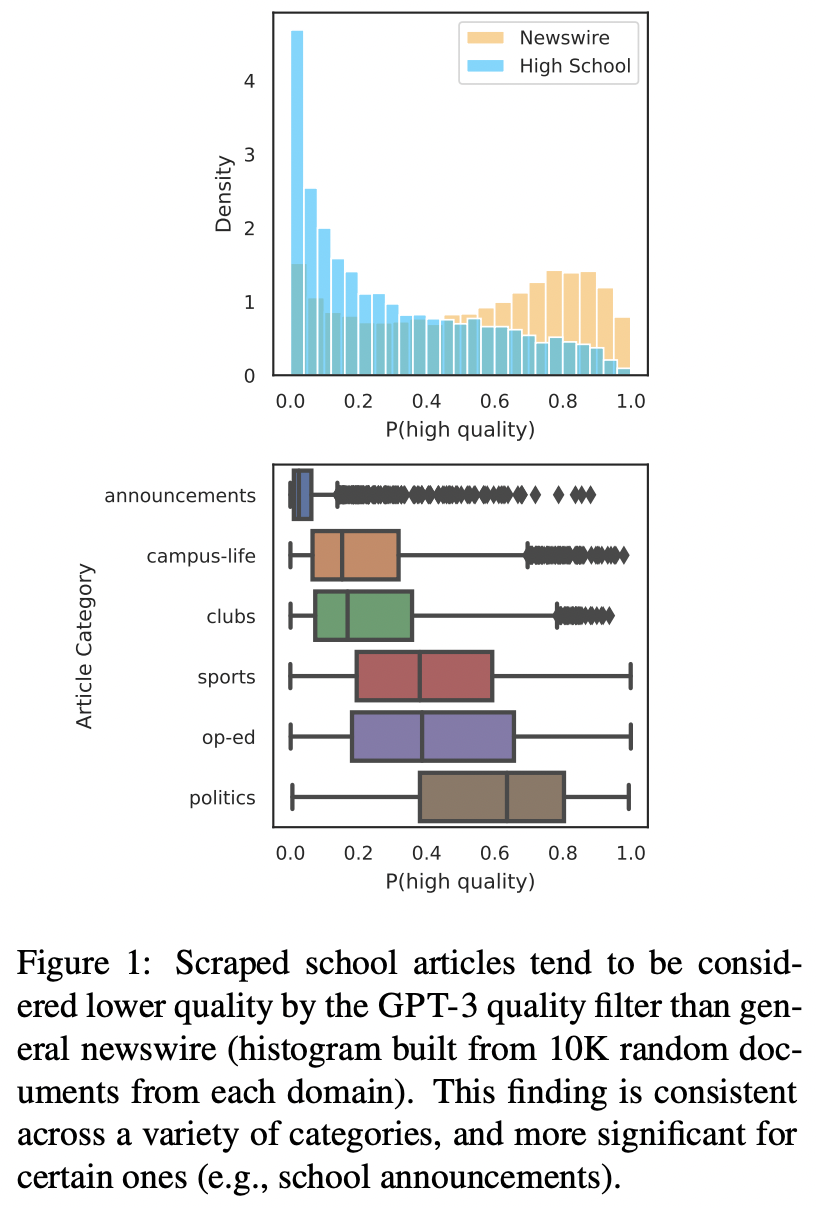
言語モデルは学習のためにウェブデータを使うが、これらのデータには望ましくない内容を含んでいることがある。そのため、Wikipedia、書籍、ニュースなどのリソースは、言語モデルに最適なテキストを自動的に選択するためのアンカーとして扱われ、一般に品質フィルタが行われている。
この論文では、全米の高校生が書いた地理情報が付与された新聞記事のデータを用いて、GPT-3の品質フィルタでどのような内容が好まれるかを調査した。その結果、裕福、教育レベルが高い、都市部、大規模校のな新聞がより高い品質と分類することがわかった。このような言語イデオロギーをテキストデータの選択に用いると、学習データに含まれる可能性の高いテキストの著者が誰であるかという点で不平等が生じることになる。そして、フィルターの品質測定は事実の正確さや文学的評価などの測定基準と整合していないことを示す。
また、言語モデルのための学習データの構築には、様々なテキストを含むか含まないかの透明性と正当性をより高める必要があることを主張している。この問題を解決する方法はこの論文で提案されていない。一方で、代表的でない著者やグループ、複数のジャンルや文体からソースを収集し、手順や除外方法を明確にすることで透明性や正当性を高めることができる。そして、倫理的な観点から学習データや事前学習済みモデルの公開予定はない。
マルチモーダルモデルの事前学習データ、アテンション機構と損失関数について調査
タイトル: Decoupling the Role of Data, Attention, and Losses in Multimodal Transformers
著者:Lisa Anne Hendricks, John Mellor, Rosalia Schneider, Jean-Baptiste Alayrac, Aida Nematzadeh
会議・出版: TACL
年: 2021
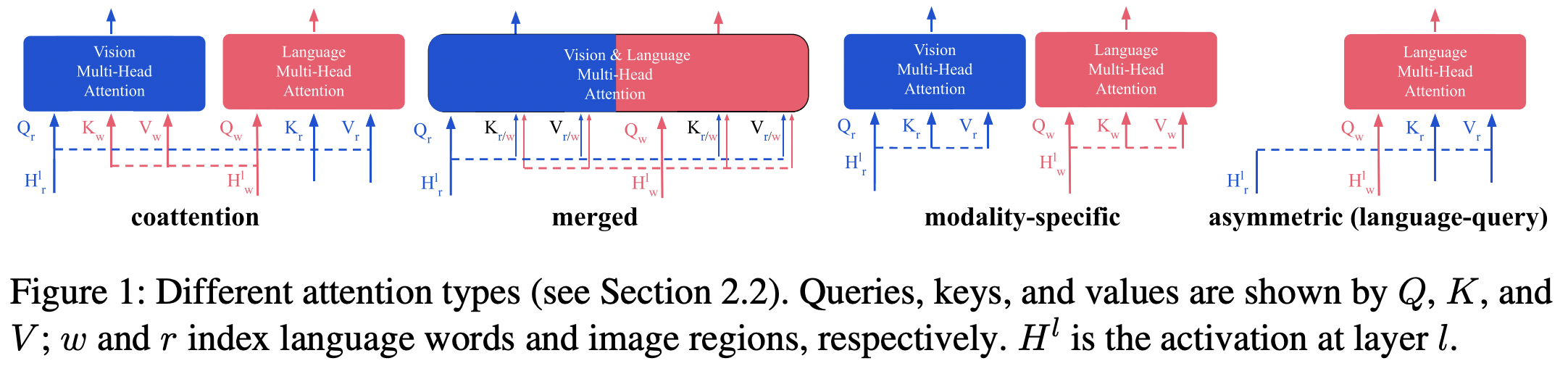
マルチモーダルモデルは画像と言語に関して豊かな表現を学習することが示唆されている。この論文では事前学習モデルの表現を評価するためにゼロショット画像検索タスクを対象として、学習された表現の質に影響を与える3つの重要な要因(1)事前学習データ(2)アテンション機構(3)損失関数について調査する。
6つのデータセットでモデルを事前学習することにより、事前学習のデータサイズよりもノイズと下流タスクとの言語類似度がモデル性能の重要な指標であることを明らかにした。また、マルチモーダルなアテンション機構を持つモデルは、画像または言語モダリティに特化したアテンション機構を持つモデルよりも性能が高いことを示した。最後に、自己教師あり学習に使用される対照学習をマルチモーダルモデルで使用した場合、性能向上が得られないことも明らかにした。
言語モデルと知識グラフを相互に考慮したQAシステム
タイトル: GreaseLM: Graph REASoning Enhanced Language Models for Question Answering
著者:Xikun Zhang, Antoine Bosselut, Michihiro Yasunaga, Hongyu Ren, Percy Liang, Christopher D. Manning, Jure Leskovec
会議・出版: ICLR
年: 2022
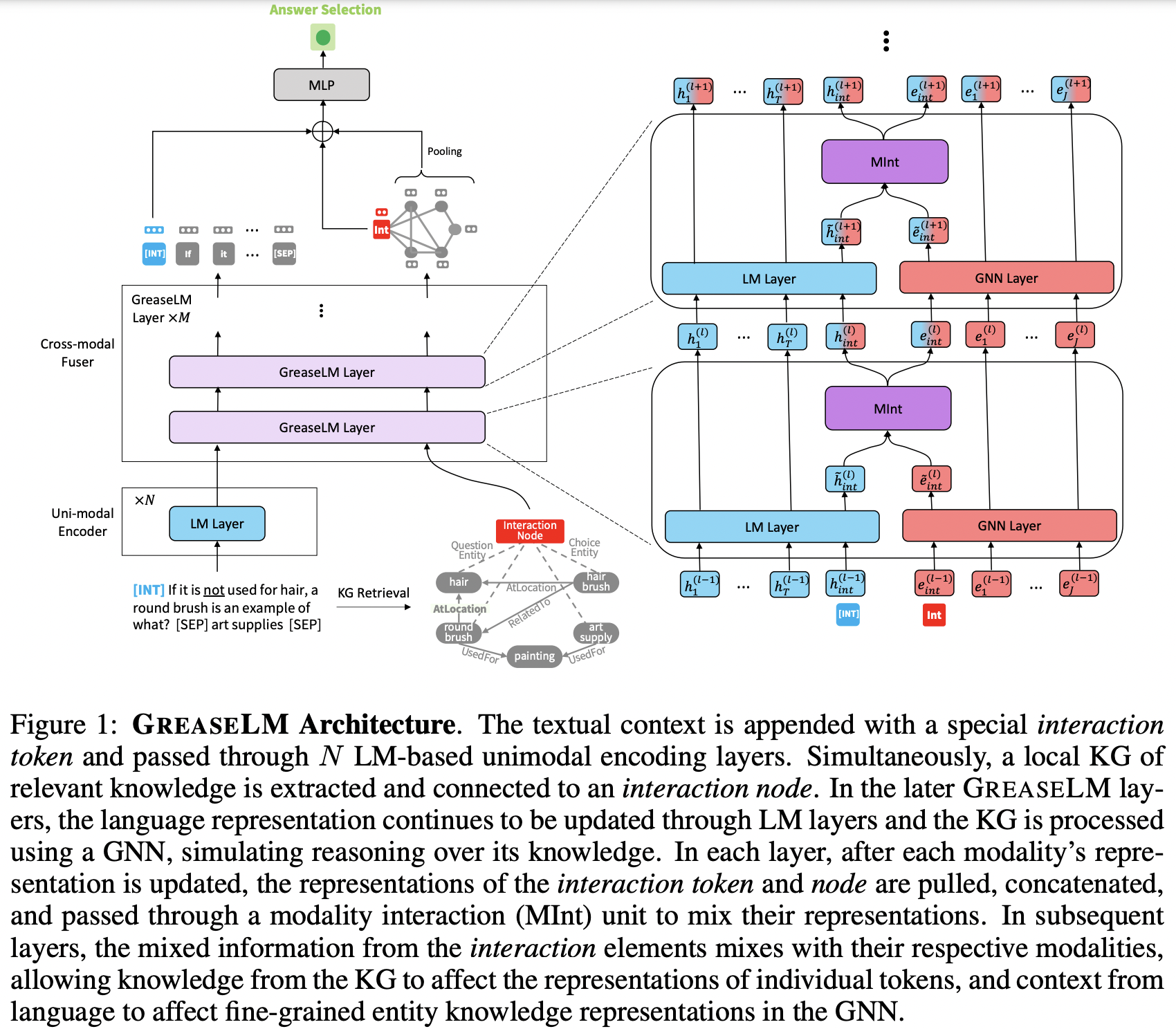
テキストによる物語に関する複雑な質問に答えるには、記述された文脈とその根底にある世界知識の両方について推論することが必要である。
しかし、既存のQAシステムの基盤となっている事前学習済みの言語モデルは、推論に必要な概念間の潜在的な関係を頑健に表現していない。知識グラフは世界知識の構造化表現として言語モデルを補強するためにしばしば用いられる。一方で、知識グラフの表現と言語情報により与えられる制約やニュアンスをどのように融合し推論するかは未解決の問題である。
この論文では、事前学習言語モデルとグラフニューラルネットワークから得られるモダリティ表現を多層的に融合する新しいモデルGREASELMを提案する。両モダリティからの情報を伝搬しあうことで言語表現は構造化された世界知識によって基礎づけられ、文脈中の言語のニュアンスを知識のグラフ表現に提供することが可能になる。3つのベンチマークで評価した結果、GREASELMは状況制約と構造化知識の両方に対する推論を必要とする質問に対して8倍大きいモデルよりも性能が高いことを示した。

