
論文メモ:ブラックボックス設定のプロンプト学習、プログラム形式の推論のための事前学習POET、経済的公平さと繁栄のための民主的AI
💡 概要
- ブラックボックス設定における事前学習モデルのプロンプト学習
- プログラム形式のデータで事前学習された推論手法POET
- 経済的公平さと繁栄を両立するための民主的AI
ブラックボックス設定における事前学習モデルのプロンプト学習
タイトル: Black-box Prompt Learning for Pre-trained Language Models
著者:Shizhe Diao, Xuechun Li, Yong Lin, Zhichao Huang, Tong Zhang
会議・出版: arXiv
年: 2022
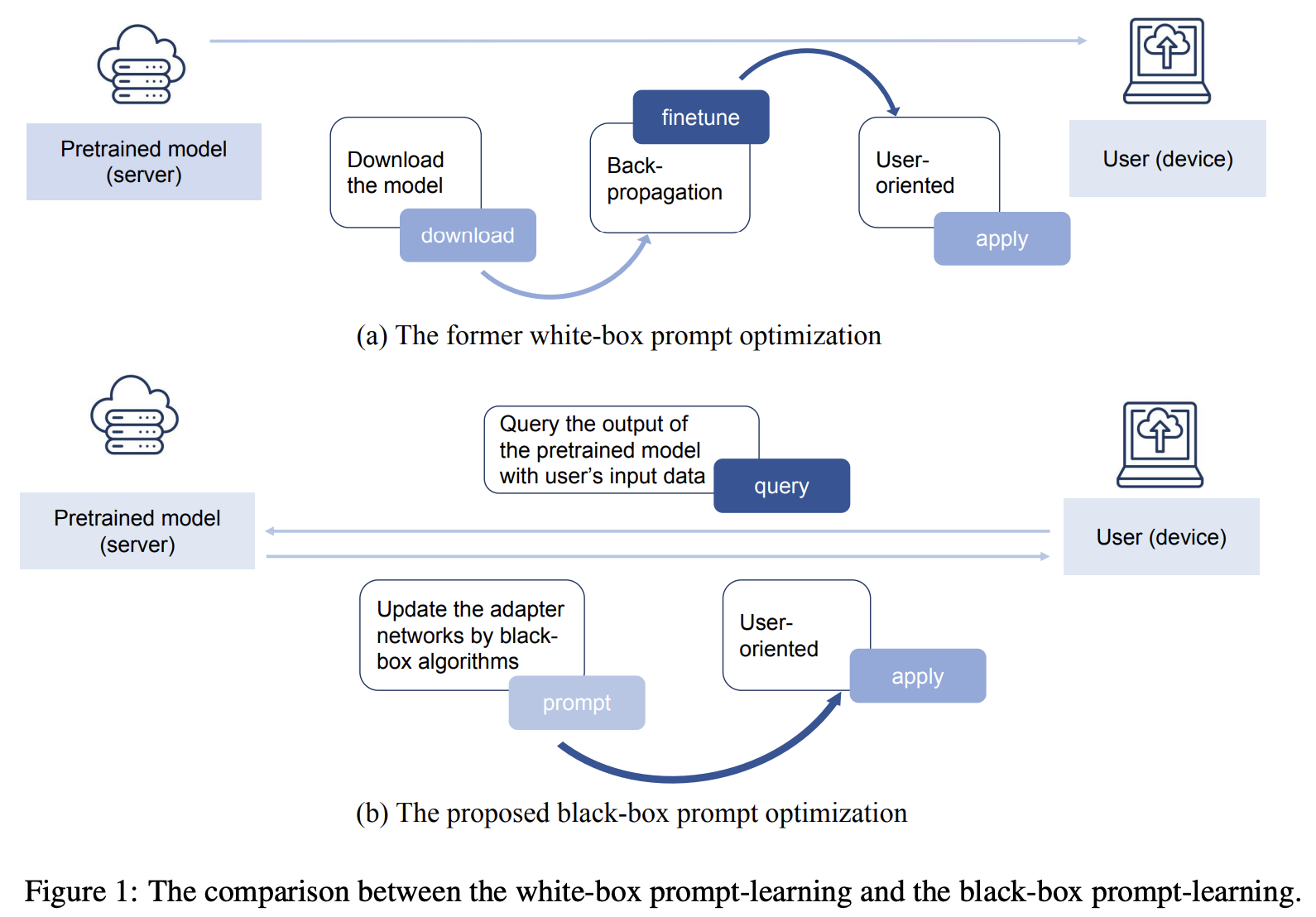
大規模な事前学習済み言語モデルに対するドメイン固有のfine-tuingが大きな注目を集めている。既存研究ではモデルの構造やパラメータにアクセス可能であり、これをホワイトボックス設定と呼ぶ。
この論文では、入力が与えられたときの出力を除いて事前学習モデルにアクセスできない新しいシナリオを考察し、この問題をブラックボックス設定と呼ぶ。ブラックボックス設定では事前学習モデルにアクセスできないため、プロンプトを更新するための勾配の逆伝播を行えない。
まず、この論文ではテキスト分類に関するブラックボックス設定を定義する。そして、解決策であるブラックボックスプロンプトを提案する。ブラックボックスプロンプトではNESアルゴリズムを用いて勾配を近似しプロンプトを更新する。実験により、提案手法は8個のデータセットにおいてSoTAを達成した。
プログラム形式のデータで事前学習された推論手法POET
タイトル: Reasoning Like Program Executors
著者:Xinyu Pi, Qian Liu, Bei Chen, Morteza Ziyadi, Zeqi Lin, Yan Gao, Qiang Fu, Jian-Guang Lou, Weizhu Chen
会議・出版: arXiv
年: 2022
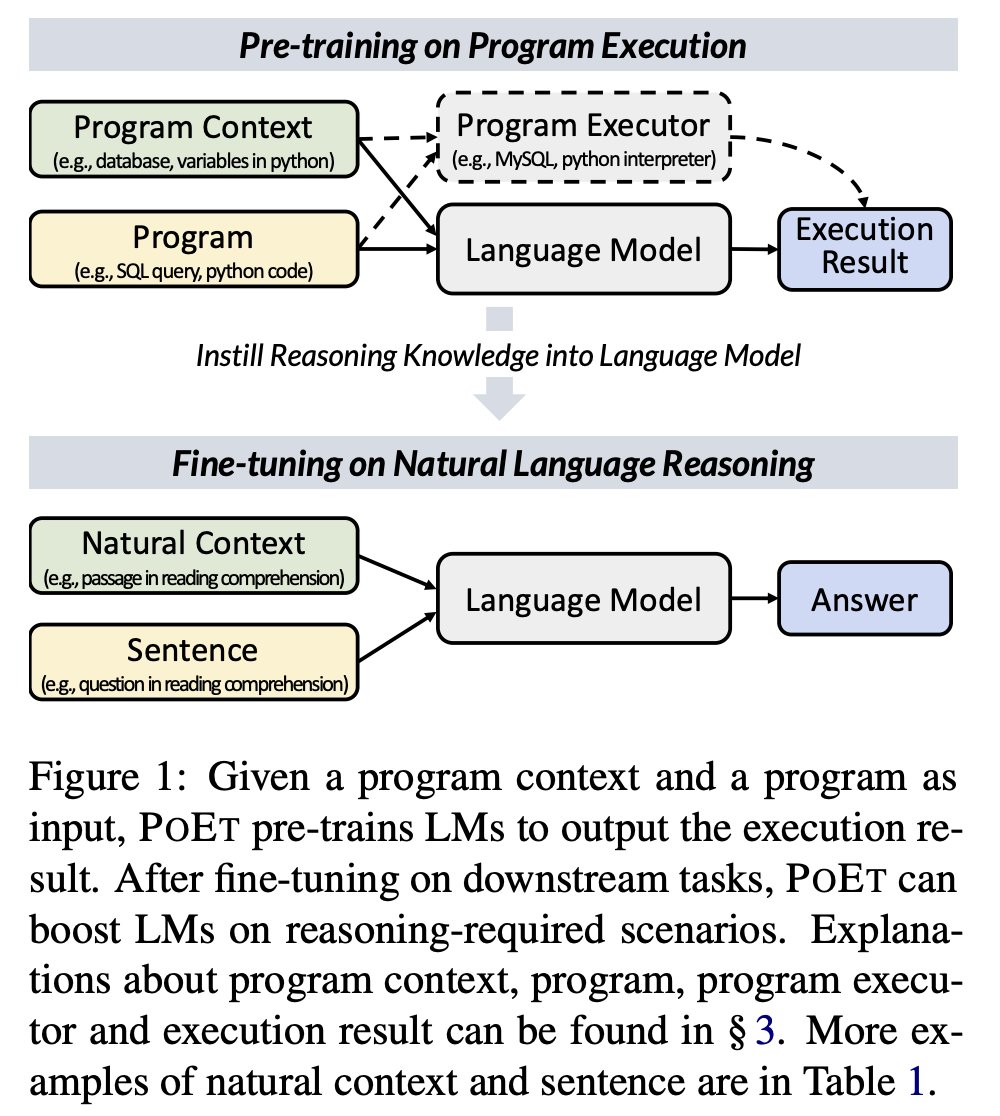
自然言語による推論は自然言語処理コミュニティにとって長年の目標である。テキストデータで事前学習された言語モデルを用いることが一般的であるが、既存の言語モデルでは推論が不十分であることが研究により示されている。本論文では新しい事前学習手法であるPOETを提案している。プログラムとその実行形式のデータにより言語モデルを事前学習することで、POETは推論知識を言語モデルに学習させる。
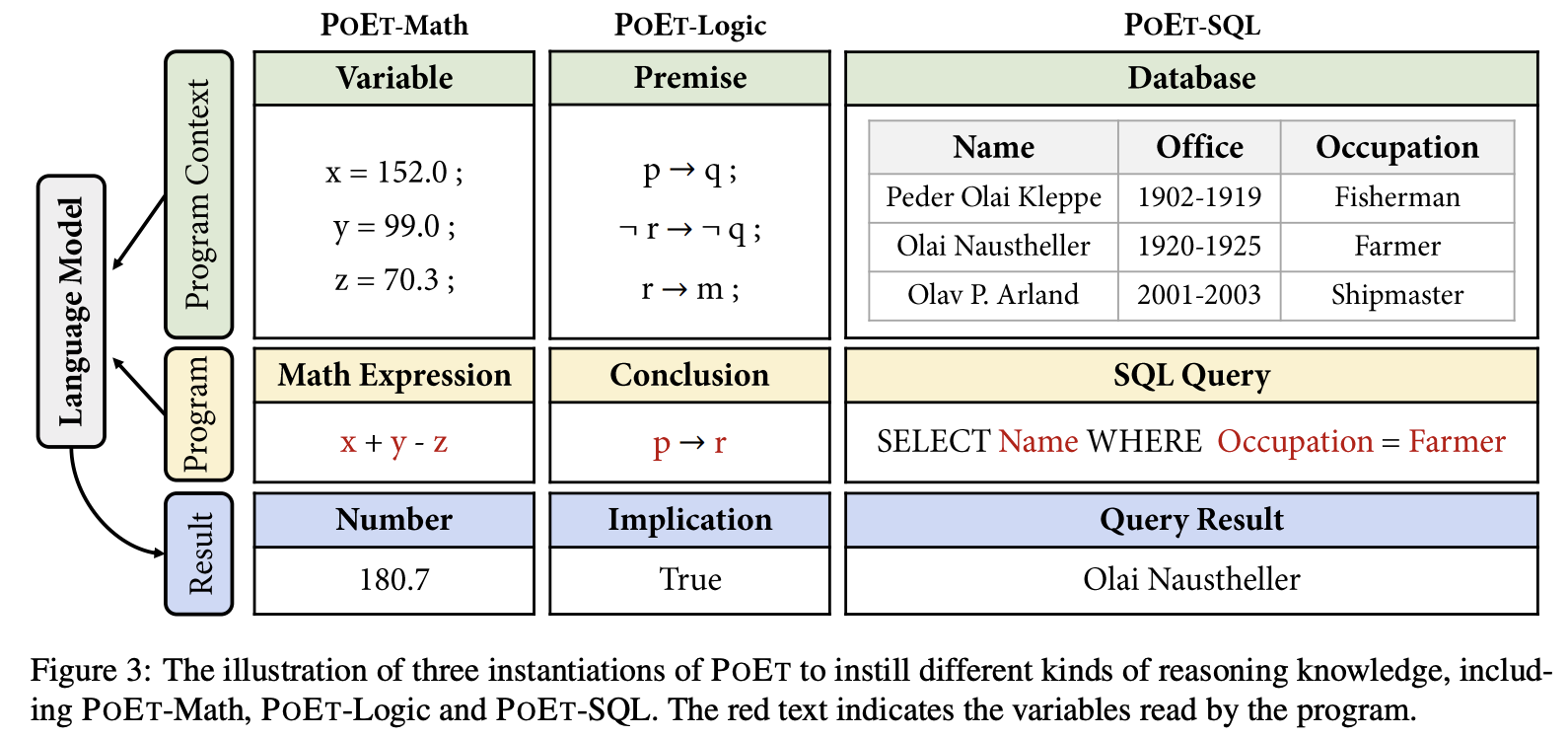
この論文では、POET-Math, POET-Logic, POET-SQLの3つのインスタンスを紹介している。6つのベンチマークに対する実験結果から、POETは数値推論、論理推論、マルチホップ推論などの自然言語推論のモデル性能を大幅に向上させることができることを実証した。
特にDROPベンチマークでは、POETはBARTのF1指標を69.2%から80.6%に向上させた。さらに、POETは大規模言語モデルで最も効果を発揮し、T5-11BのF1スコアで87.6%のSoTAを達成した。
経済的公平さと繁栄を両立するための民主的AI
タイトル: Human-centered mechanism design with Democratic AI
著者:Raphael Koster, Jan Balaguer, Andrea Tacchetti, Ari Weinstein, Tina Zhu, Oliver Hauser, Duncan Williams, Lucy Campbell-Gillingham, Phoebe Thacker, Matthew Botvinick, Christopher Summerfield
会議・出版: arXiv
年: 2022
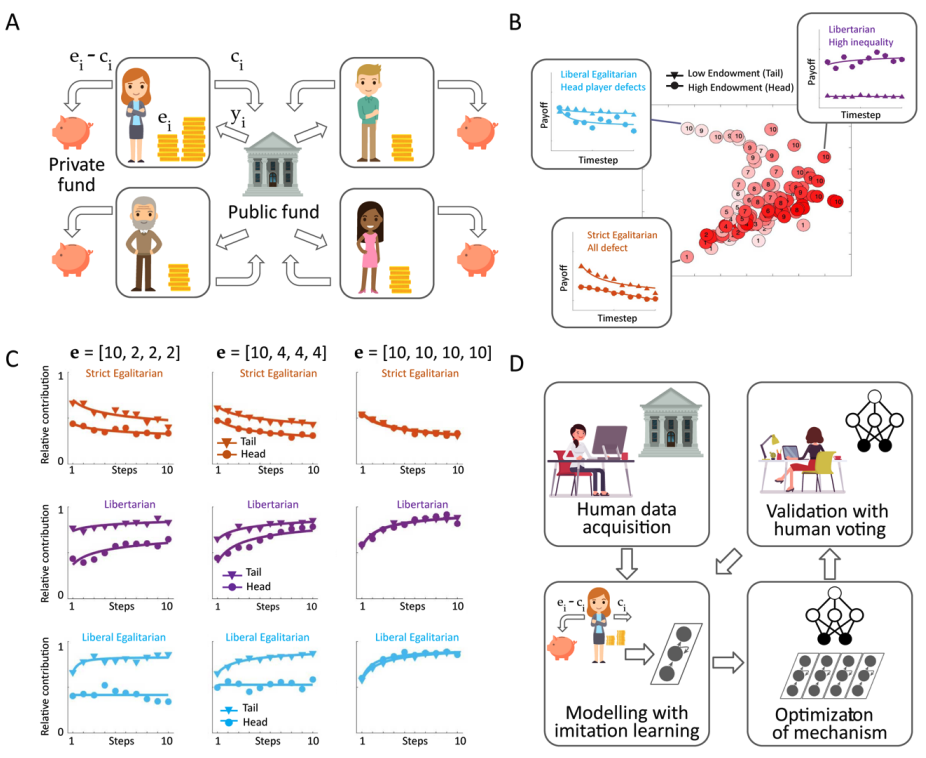
人間が集団で行動して富を生み出すとき、その収益を公平に、しかし繁栄を損なわないように分配する仕組みが必要である。一方で、人間の価値観に沿ったAIの構築はまだ未解決な問題である。
そこで、強化学習をにより人間が多数決で好む社会的な仕組みを設計する民主的AIと呼ばれるヒューマンインザループ手法を開発した。そのために、人間が参加する実際のお金を使ったオンライン投資ゲームを行った。このゲームで金銭を集団的な利益のために他者と共有するまたは共有しないを決定することができる。共有された収益は、AIが設計したものと人間が設計した2つの異なる再分配の仕組みでプレイヤーに還元される。人間が過半数で投票する再分配の仕組みを設計するためにAIシステムを学習する。
その結果、人間が設計した再分配の仕組みや、様々なベースラインよりもAIが設計した仕組みの方が人気があることが分かった。そして、AIは富の不均衡を改善し、フリーライダーを制裁する仕組みを発見した。人間の嗜好に最適化することで、民主的AIは価値に沿った政策革新のための有望な手法となる可能性がある。

