
論文メモ:知識蒸留と枝刈りによる公平性改善、モデル出力の一貫性を評価するDiscoScore、寄与率による説明性に対する人間の理解、特徴量による説明性は人間理解への貢献を検証
💡 概要
- 知識蒸留と枝刈りによるモデル圧縮は公平性を改善する
- テキスト生成モデルの一貫性を評価するDiscoScore
- 寄与率による説明性に対する人間の理解について分析
- 特徴量による説明性は人間のモデルの性能への理解に貢献するかを検証
知識蒸留と枝刈りによるモデル圧縮は公平性を改善する
タイトル: Can Model Compression Improve NLP Fairness?
著者:Guangxuan Xu, Qingyuan Hu
会議・出版: arXiv
年: 2022
大規模な言語モデルを用いることは様々なタスクで有効であることが知られている。そして、知識蒸留や枝刈りによる大規模モデル圧縮が注目されているが、圧縮がモデルの公正さに及ぼす影響については十分に調査されていない。
本論文は言語モデルの有害さと偏りに対する蒸留と刈り込みの効果を検証した。GPT2に対して知識蒸留と枝刈りの手法を適用し、モデル蒸留後に有害さとバイアスが減少することを発見した。
この結果は圧縮を用いて公平なモデルを開発する可能性を示唆するものである。一方で、正則化とモデルの頑健性に関連しているという仮説を立てたが、この関連を検証するためにはさらなる実験と理論的裏付けが必要である。
テキスト生成モデルの一貫性を評価するDiscoScore
タイトル: DiscoScore: Evaluating Text Generation with BERT and Discourse Coherence
著者:Wei Zhao, Michael Strube, Steffen Eger
会議・出版: arXiv
年: 2022

文の相互依存性をモデル化するなど談話一貫性の観点からテキスト生成モデルを設計することに関心が高まっている。しかし、最近のBERTベースの評価指標では、一貫性を認識できず、システム出力に含まれる一貫性に欠ける要素を減点することができない。
本研究では、BERTを用いて読者のフォーカスに着目するセンタリング理論により異なる視点から談話一貫性をモデル化した評価指標であるDiscoScoreを紹介する。
実験ではDiscoScoreと一般的な一貫性を評価するモデルを含む16の非談話及び談話指標を網羅し、要約と文書レベルの機械翻訳で評価した。その結果、(1)BERTベースの指標の多くはは10年前に提案された初期の談話指標よりも人間が評価した一貫性との相関がはるかに悪い、(2)最新の評価指標であるBARTScoreは、システムレベルの比較において弱点があることを明らかにした。
これに対して、DiscoScoreは一貫性だけでなく事実との一致のにおいて人間の評価とシステムレベルで強い相関を達成した。BARTScoreとの比較では、平均で10ポイント上回る相関を示した。
寄与率による説明性に対する人間の理解
タイトル: Human Interpretation of Saliency-based Explanation Over Text
著者:Hendrik Schuff, Alon Jacovi, Heike Adel, Yoav Goldberg, Ngoc Thang Vu
会議・出版: arXiv
年: 2022
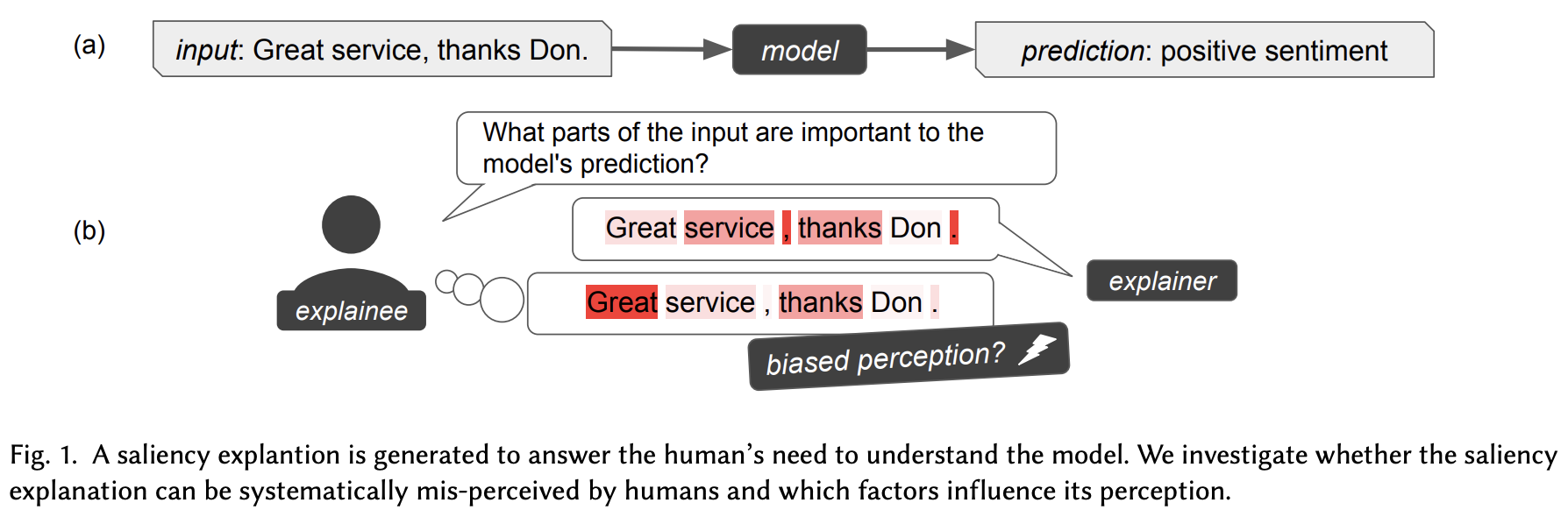

説明可能なAIの多くの研究は効果的な説明を生成することに焦点を当てているが、実際に人間がどのように説明を理解し解釈するかについて焦点を当てた研究はあまりない。
本研究では、入力単語の寄与率に基づく説明の研究を通じてこの問題に注目する。テキストモデルの寄与率による説明性は入力テキストのどの単語がモデルの決定に対して他の単語よりも影響力があったかを伝える。勾配に基づく方法やシャープレイ値に基づく方法は、数学的に寄与率を提供していることがわかっている。しかし、説明を受けた人間はどのようにそれを理解するのか?また、その理解はモデルの説明が伝えようとしたものと一致しているのだろうか?これらの疑問に答えるために、入力、Feature Attribution、可視化手順などの様々な要因が人間の説明の理解に与える影響を実証的に調査する。英語とドイツ語のタスクに対するクラウドワーカーのモデルの説明に関する回答に対してGAMMモデルを適用した。
その結果、説明の重要性を直接的に伝えているにもかかわらず単語の長さや文の長さなどの表層的で直接関係ない要因が、人間のの重要性の割り当てに影響を与え説明の理解を誤ることがわかった。また、ヒートマップに代わる寄与率の可視化手法として棒グラフを提案する。特定の要因による説明に対する歪曲効果を減衰させ、より良い寄与率のCalibration(モデルの出力値を実際の分布に近づけること)を導くことができることを発見した。
特徴量による説明性は人間のモデルの性能への理解に貢献するかを検証
タイトル: Explain, Edit, and Understand: Rethinking User Study Design for Evaluating Model Explanations
著者:Siddhant Arora, Danish Pruthi, Norman Sadeh, William W. Cohen, Zachary C. Lipton, Graham Neubig
会議・出版: AAAI
年: 2022

機械学習モデルの予測を説明する試みとして、重要だと思われる特徴量を予測結果の要因とする手法はたくさん提案されている。これらの手法は人間のモデルに対する理解を向上させる可能性があると主張されているが、明示的に検証した研究はほとんどない。
そのため、この論文では人間がホテルのレビューの本物と偽物を区別するために訓練された検出モデルと作業する、クラウドソーシングによる調査を実施する。クラウドワーカーは、学習データとは別のレビューに対してモデルの予測を再現することと、もともと予測されたクラスの確率を下げる、つまり敵対的なレビューを作成することを目標にレビューを編集することの両方に挑戦する。クラウドワーカーの学習段階のデータは入力スパンの寄与率を伝えるためにハイライトされる。
実験の結果、線形bag-of-wordsモデルに対して、クラウドワーカーの学習段階において特徴量にアクセスできる場合(説明あり)は、特徴量にアクセスできない場合(説明なし)と比較してテスト段階でモデルの信頼性を大きく低下させることができることがわかった。そして、BERTベースの分類器では一般的な局所的な説明は、説明なしの場合よりもモデル信頼度を低下させるクラウドワーカーの能力を向上させなかった。一方で、BERTモデルを模倣して訓練された線形モデルの説明がBERTモデルの説明として有用であることが示された。

