
論文メモ:CNNとTransformer事前学習モデルの比較、ルールベースと深層学習を統合した手法DEEPCTRL、アテンション機構の説明性に対する忠実性の調査
💡 概要
- CNN事前学習モデルはTransformer事前学習モデルに匹敵する
- 深層学習モデルにルールベースを制御し考慮する手法DEEPCTRL
- 説明性におけるアテンション機構の重みとモデル予測の忠実性の間の整合性調査
CNN事前学習モデルはTransformer事前学習モデルに匹敵する
タイトル: Are Pre-trained Convolutions Better than Pre-trained Transformers?
著者:Yi Tay, Mostafa Dehghani, Jai Gupta, Dara Bahri, Vamsi Aribandi, Zhen Qin, Donald Metzler
会議・出版: ACL
年: 2021
事前学習モデルにおいてTransformerは最も標準的な選択肢になっている。一方で、最近の研究では畳み込みニューラルネットワーク(CNN)も有望性が示されているが、事前学習モデルにおいて検討は行われていない。
本研究では事前訓練と非事前訓練の両方に関してモデル構造としてCNNはTransformerと競合するかどうかを調査する。そして、実行時間、スケーラビリティ、FLOPS数、モデルの品質に関する注意点とトレードオフについても議論する。
8つのデータセット/タスクに関する広範な実験を通して、CNNベースの事前学習済みモデルは特定のシナリオにおいてTransformerの対応するモデルよりも優れており、競争力があることを発見した。事前学習されたTransformerはデファクトスタンダードのモデル構造であるが、この論文の結果は特定のシナリオでは最適でない可能性があることを示している。そのため、事前学習とモデル構造は独立して考慮する必要がある。
深層学習モデルにルールベースを制御し考慮する手法DEEPCTRL
タイトル: Controlling Neural Networks with Rule Representations
著者:Sungyong Seo, Sercan O Arik, Jinsung Yoon, Xiang Zhang, Kihyuk Sohn, Tomas Pfister
会議・出版: NeurIPS
年: 2021
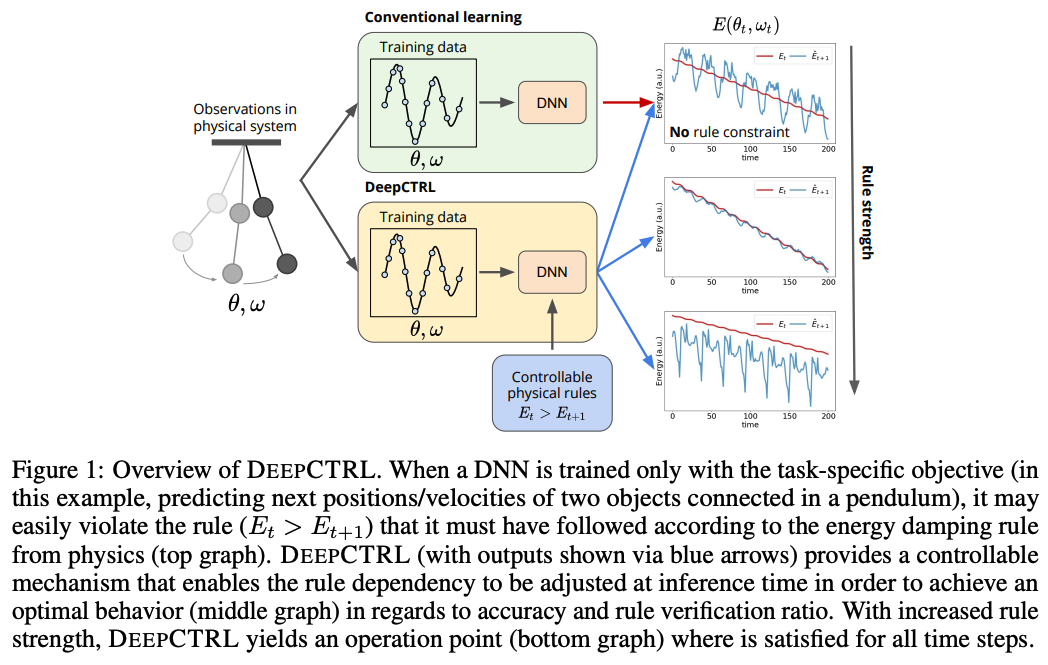
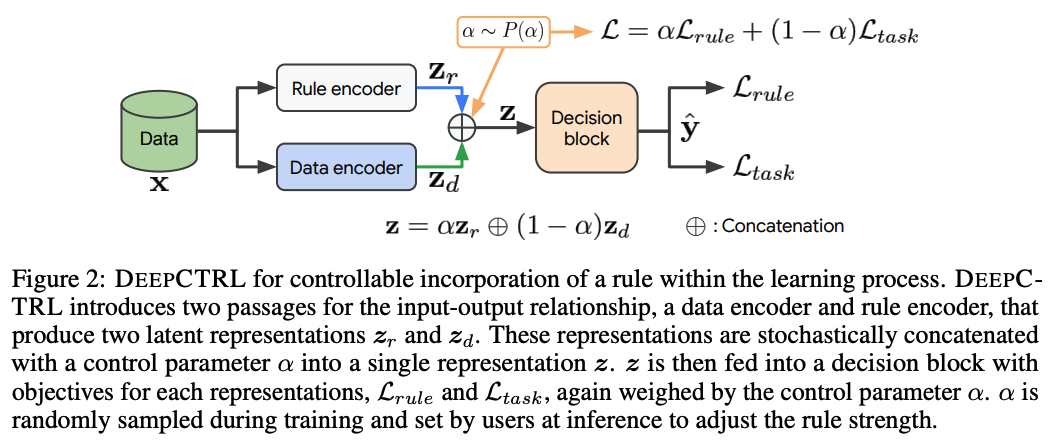
ニューラルモデルは学習データの規模と網羅性が大きくなるほどより正確な結果が得られます。高品質で大規模なラベル付きデータセットを用いることはモデル改善のための1つの方法です。これとは別に、「ルール」(推論ヒューリスティック、方程式、連想論理、または制約などの事前知識)を活用する方法がある。
ルールベース手法を深層学習モデルに統合し、推論時にルールベース手法と深層学習モデルのどちらをより考慮するかを制御可能できる新しい学習手法であるDEEPCTRLを提案する。DEEPCTRLはデータの形式やモデル構造に依存しない。さらに、DEEPCTRLの重要な点としてルールベースを考慮するために学習済みモデルの再学習を必要とせず、推論時にユーザ自身が調整することができる。
物理、小売、ヘルスケアなどのルールを組み込むことが重要な実世界のドメインにおいてDEEPCTRLは有効性を示した。ルールベースを考慮する割合を大幅に向上させることで、学習済みモデルの信頼性と信用性を向上させ同時に下流タスクでの精度向上も実現した。
説明性におけるアテンション機構の重みとモデル予測の忠実性の間の整合性調査
タイトル: Rethinking Attention-Model Explainability through Faithfulness Violation Test
著者:Yibing Liu, Haoliang Li, Yangyang Guo, Chenqi Kong, Jing Li, Shiqi Wang
会議・出版: arXiv
年: 2022
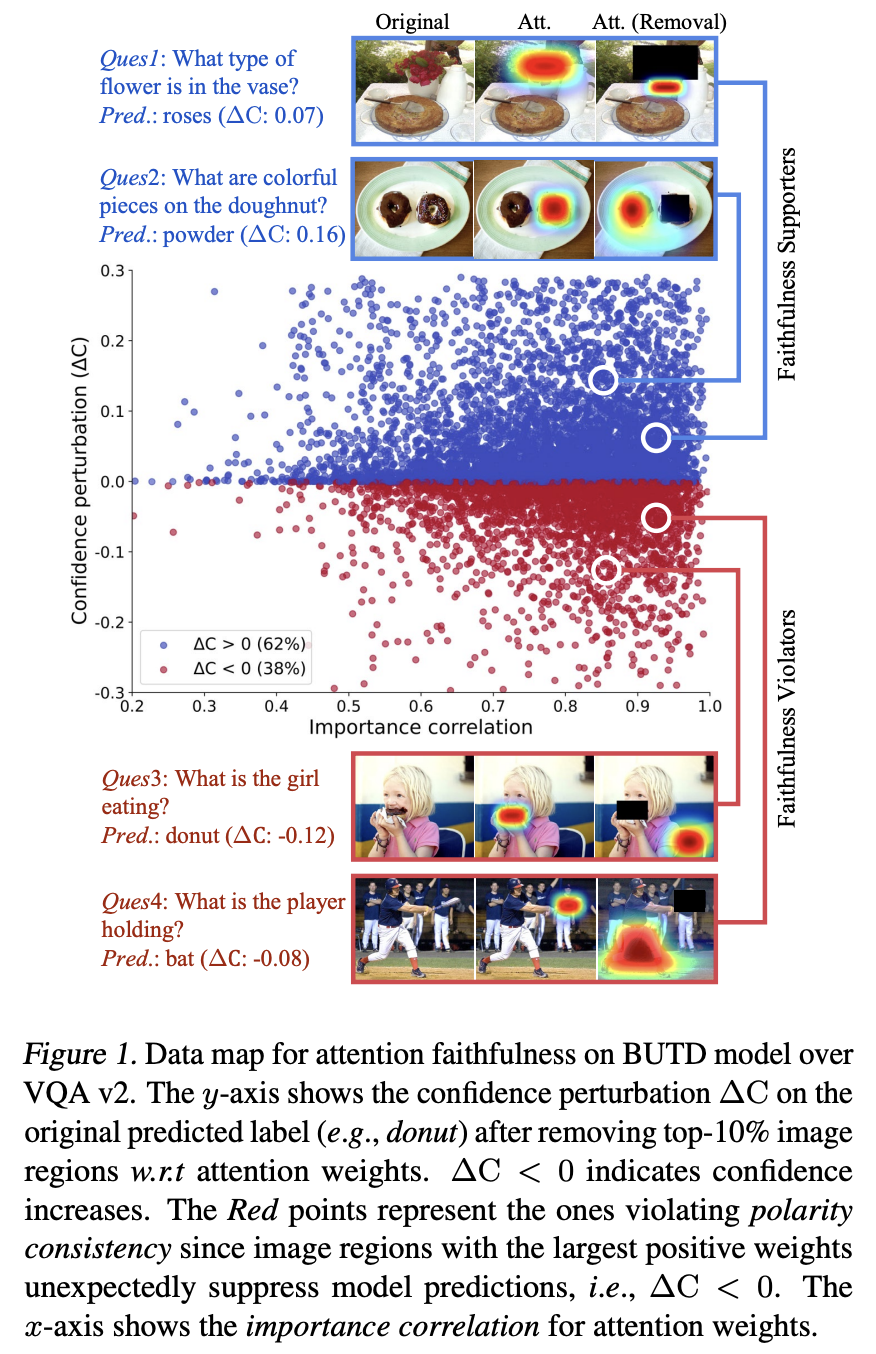
アテンション機構はニューラルモデルの説明性の文脈で語られることが多い。アテンション機構は入力に対する確率分布を生成し、特徴量の重要性を示す指標として広く認識されている。
一方で、本論文ではアテンション機構の説明性には重大な限界があることを発見した。特徴の影響の極性を特定することが弱いことである。ここでアテンション機構の極性とは、注目度の高い素性はモデル予測に忠実に寄与せず、逆に抑制する効果を与える可能性があるということである。この発見を基に勾配やLRPベースのアテンション機構などの既存手法の説明可能性について考察する。
まず、アテンション機構の重みと極性の間の整合性を測定するための手法 (faithfulness violation test) を提案する。そして、広範な実験を通してテストされたほとんどの説明性が、抑制効果により予想外に妨げられていることを示す。

