
論文メモ:多言語音声言語モデルmSLAM、ニューラルネットワークの忘却は必要、事前学習モデルを効率化するpNLP-Mixer
💡 概要
- 51言語の音声データと101言語のテキストデータで学習された多言語音声言語モデルmSLAM
- ニューラルネットワークの忘却、実は性能改善に寄与している
- 射影ベースのMLP-Mixerにより事前学習モデルを効率化するpNLP-Mixer
51言語の音声データと101言語のテキストデータで学習された多言語音声言語モデルmSLAM
タイトル: mSLAM: Massively multilingual joint pre-training for speech and text
著者:Ankur Bapna, Colin Cherry, Yu Zhang, Ye Jia, Melvin Johnson, Yong Cheng, Simran Khanuja, Jason Riesa, Alexis Conneau
会議・出版: arXiv
年: 2022
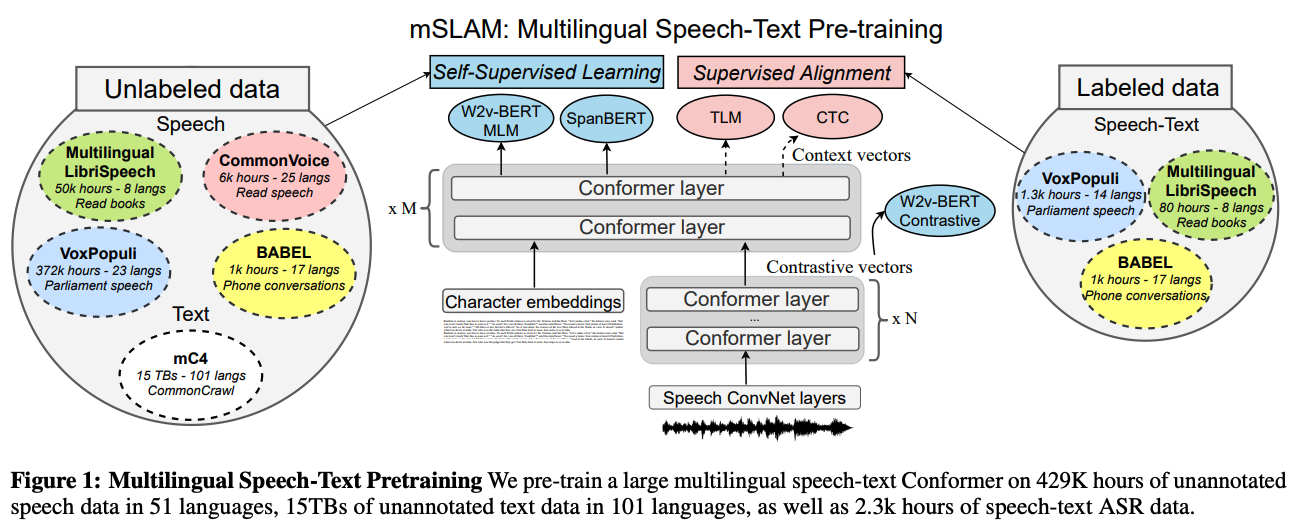
multilingual Speech and LAnguage Model (mSLAM) は多言語のラベル付けされていない大量の音声データとテキストデータに対して事前学習を行い、音声とテキストの表現を学習する多言語音声言語モデルである。mSLAMは、51言語のラベル無し音声をw2v-BERTで、101言語の文字レベルテキストをSpanBERTで学習させたモデルである。また、これらのラベル無しデータに加え、音声表現とテキスト表現の共有を促進するために少量の音声とテキストのパラレルデータに対してもmSLAMを学習させる。
mSLAMをいくつかの音声理解タスクで評価し、テキストと音声の両方を考慮した事前学習が音声のみの事前学習と比較して、音声翻訳、発話意図分類、音声言語IDの性能を向上させ多言語ASRで高い性能であることを明らかにした。また、mSLAMは音声とテキストの両方でfine-tuningを行うことができfine-tuningにおいてテキストのパラレルデータを直接利用することで、音声翻訳の品質をさらに向上させることができる。また、XNLI文対分類において大量のパラレルデータを持つ(ヨーロッパ)言語ではmSLAMの半分のサイズのテキストのみのモデルと同等のゼロショット性能を達成した。一方で、パラレルデータの少ない言語では深刻な品質劣化を示した。
ニューラルネットワークの忘却、実は性能改善に寄与している
タイトル:Fortuitous Forgetting in Connectionist Networks
著者:Hattie Zhou, Ankit Vani, Hugo Larochelle, Aaron Courville
会議・出版: ICLR
年: 2022
忘却は人間や機械学習の両方においてあまり好ましくない性質と見なされている。例えば、ニューラルネットワークにおいて破壊的忘却はよく知られた忘却に関する問題である。
しかし、この論文では忘却はむしろ機械学習にとって好ましいものであることを示す。ニューラルネットワークの学習過程の枠組みとして「忘却と再学習」を紹介する。忘却ステップではモデルから望ましくない情報を選択的に除去し、再学習ステップでは異なる条件において一貫して有用な情報を強化する。
「忘却と再学習」の枠組みは、画像や言語の多くの既存のiterative学習アルゴリズムを統合し、望ましくない情報の忘却という観点から、これらのアルゴリズムの成功を理解することを可能にする。これらの結果を元により適切な忘却機構を設計することで、既存のアルゴリズムを改善することができる。
射影ベースのMLP-Mixerにより事前学習モデルを効率化するpNLP-Mixer
タイトル:pNLP-Mixer: an Efficient all-MLP Architecture for Language
著者:Francesco Fusco, Damian Pascual, Peter Staar
会議・出版: arXiv
年: 2022
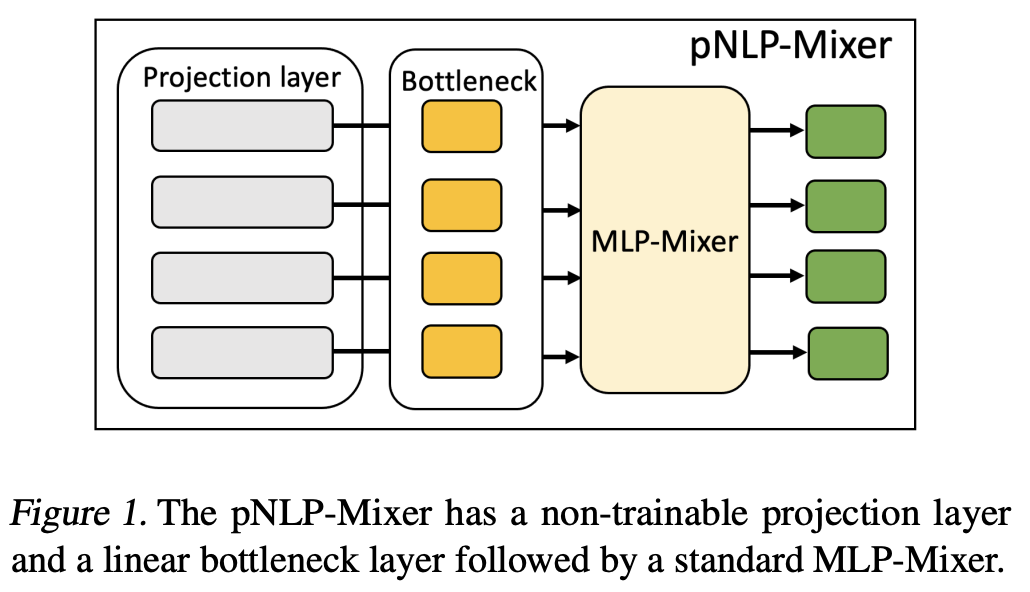
大規模な事前学習済み言語モデルは、自然言語処理様々なタスクの状況を一変させた。限られた数のアノテーションしか存在しないタスクでも高い性能を実現できるが、推論において計算コストに関して依然として課題がある。これらを解決するために主に2つの方法が知られている。1つ目はpruning、量子化やmixed precisionなどと組み合わせて高度に最適化されたハードウェアを用いて高速化する方法である。2つ目は、大規模モデルをよりパラメータ数が少ないモデル(例:RNN)に置き換えることで高速化する方法です。
本論文では、射影ベースのMLP-Mixerを用いたpNLP-Mixerによって重み効率を改善する。これはより効率的なモデルに置換する2つ目の手法に属する。MLP-MixerはRNNなどと違い並列化でき、Transformerと違い計算量は文長の線形に依存するだけであり長距離の依存構造も考慮することができる。
pNLP-Mixerを2つの多言語意味解析データセットで評価した。その結果、pNLP-Mixerは38倍のパラメータを持つmBERTとほぼ同等の性能を示し、3倍少ないパラメータで最先端の効率的なモデル(pQRNN)を上回る性能を示しました。

