
論文メモ:訓練不要な層に置換することによる高速化、翻訳モデルの出力による評価モデルの弱点分析、学習設定のデータスケーリング法則への影響、多言語言語モデルXGLM
💡 概要
- 訓練可能な層を訓練不要な層に置換することによる高速化
- 評価モデルに対して翻訳モデルを最適化することで評価モデルの弱点を分析
- 学習設定がデータスケーリングの法則に与える影響
- 大規模多言語言語モデルXGLMのfew-shot学習とzero-shot学習の調査
訓練可能な層を訓練不要な層に置換することによる高速化
タイトル: Learning Features with Parameter-Free Layers
著者:Dongyoon Han, YoungJoon Yoo, Beomyoung Kim, Byeongho Heo
会議・出版: ICLR
年: 2022
畳み込みブロックのような学習可能な層は、連続した空間の演算によってグローバルな文脈を捉えるためのパラメータを学習しており、標準的なネットワーク設計の選択肢となっている。効率的なネットワークを設計する場合、深さ方向の畳み込みなどの学習可能な層はパラメータ数とFLOPsの効率化が可能であるが、実際にはモデル速度の向上はほとんど得られない。
本論文では、ネットワーク構造において演算を効率的な訓練可能な層に置き換えるのではなく、シンプルな訓練不要なパラメータフリー演算に置き換えることが速度に関して有効であることを明らかにする。これはネットワーク構造の演算を訓練可能な層で構成するという固定観念を打破することを目的とする。
max-poolやavg-poolのような訓練不要な演算が機能するかどうかを調べるために、訓練されたモデルによる層レベルの調査とネットワーク構造の探索により訓練不要な演算の置換について広範な実験分析を行う。この調査により、モデルの精度をそれほど犠牲にすることなく、訓練不要な演算を主要な構成要素としてモデルに用いるアイデアを得る。ImageNetデータセットにおける実験の結果、訓練不要な演算を用いたネットワーク構造は、モデル速度、パラメータ数、FLOPsの面でさらなる効率化のメリットを享受できることが実証された。
評価モデルに対して翻訳モデルを最適化することで評価モデルの弱点を分析
タイトル: Identifying Weaknesses in Machine Translation Metrics Through Minimum Bayes Risk Decoding: A Case Study for COMET
著者:Chantal Amrhein, Rico Sennrich
会議・出版: arXiv
年: 2022

機械翻訳においてニューラルネットワークを用いた評価指標は人間の評価と高い相関を実現している。一方で、このような評価指標に対して機械翻訳モデルを最適化する前に、高いスコアを得た悪い翻訳へのバイアスを認識し排除する必要がある。
この論文ではサンプルベースのMinimum Bayes Risk (MBR) デコーディングを使用し、評価指標の弱点を見つけ定量化することができることを示した。実験では英語->ドイツ語とドイツ語->英語の翻訳に対して、ニューラルネットワークを用いた評価指標であるCOMETをMBRデコーディングに適用した。その結果、COMETは数字や名前の不一致に十分な評価を行えないことが明らかになった。さらに、これらの問題は単に擬似データを追加学習させるだけでは完全に除去できないことも示した。
学習設定がデータスケーリングの法則に与える影響
タイトル: Data Scaling Laws in NMT: The Effect of Noise and Architecture
著者:Yamini Bansal, Behrooz Ghorbani, Ankush Garg, Biao Zhang, Maxim Krikun, Colin Cherry, Behnam Neyshabur, Orhan Firat
会議・出版: arXiv
年: 2022
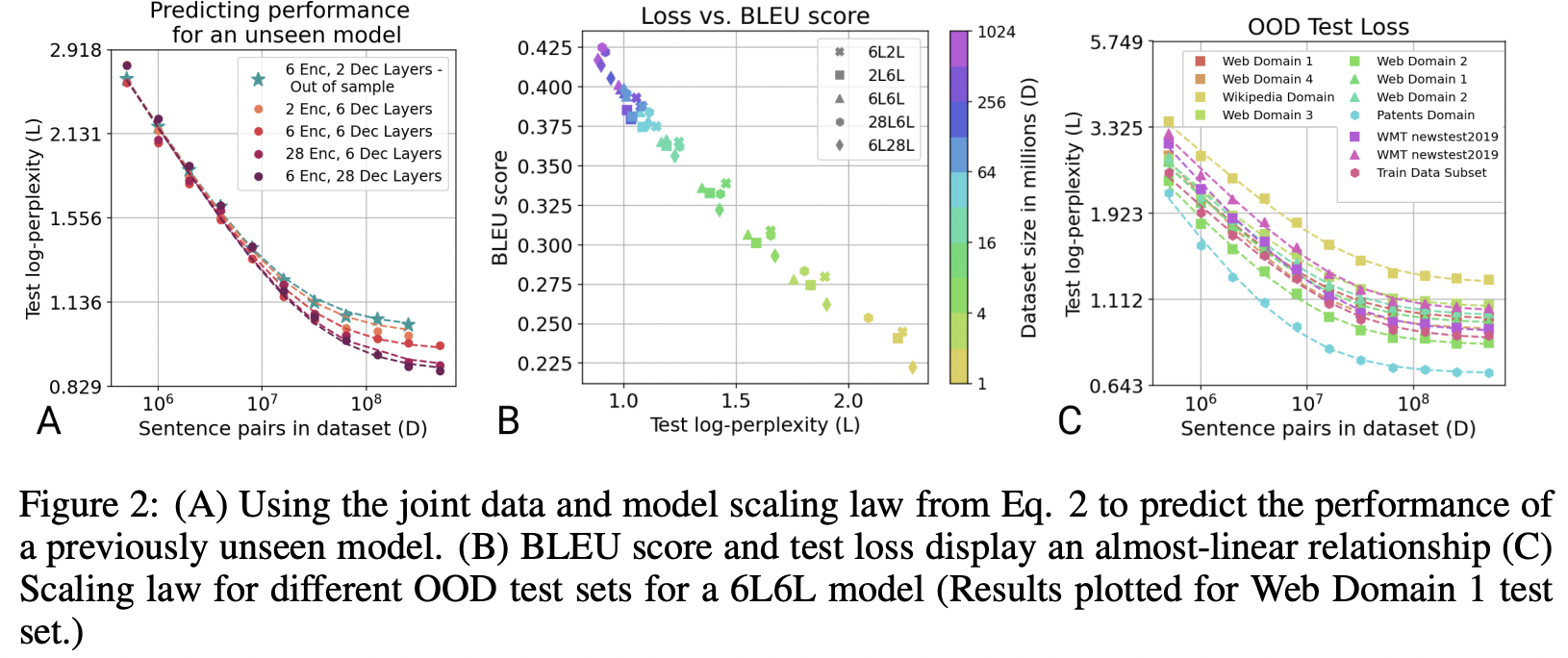
本研究では、ニューラル機械翻訳のデータスケーリングの法則を実証的に示す。まず、エンコーダ・デコーダTransformerモデルのテストデータにおける損失が、モデルサイズに依存し学習サンプル数のべき乗則でスケールすることを明らかにする。次に、学習設定の様々な要素を変更しデータスケーリングの法則にどのような影響を与えるかを調査した。
その結果、変更の大部分はスケーリング曲線の乗法的なシフトをもたらすだけで、指数はほとんど変化しないことがわかった。これはモデル構造や学習データの品質が多少悪くとも、データを追加することで補正できることを示唆している。一方で、パラレルデータではなく逆翻訳データを用いて学習分布を変更すると、スケーリング指数に影響を与えることがわかった。
大規模多言語言語モデルXGLMのfew-shot学習とzero-shot学習の調査
タイトル: Few-shot Learning with Multilingual Language Models
著者:Xi Victoria Lin, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O’Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li
会議・出版: arXiv
年: 2022
GPT-3などの大規模言語モデルは、fine-tuningなしに広範囲のタスクを処理することができる。大規模言語モデルは多くの異なる言語を同一空間上で表現できることが知られているが、学習データは英語が支配的であり言語横断的な汎化性には限界がある可能性がある。
本研究では、多様な言語を網羅しかつ言語のバランスのとれたコーパスを用いて多言語言語モデルを学習し、様々なタスクにおけるfew-shot学習とzero-shot学習の性能を調査する。その結果、75億のパラメータを持つ最大規模のモデルが20以上の代表的な言語における少数ショット学習において新たなSoTAを示し、多言語推論や自然言語推論において同一サイズのGPT-3を上回る性能を示しました。機械翻訳ベンチマークFLORES-101では、182の翻訳方向のうち171方向でGPT-3を上回り、45方向で教師ありベースラインを上回った。
また、本モデルが成功・失敗した点を詳細に分析し、いくつかのタスクにおいて言語横断的な学習を可能にしていることを明らかにした。そして、5つの言語でのヘイトスピーチ検出などの社会的価値のあるタスクで言語モデルを評価し、GPT-3モデルと同様の限界があることもわかった。

